Дисперсия свойства. Высшие моменты суммы случайных величин
Дисперсия случайной величины и ее свойства.
Многие случайные величины имеют одинаковое математическое ожидание, но различные возможные значения. Поэтому одного математического ожидания недостаточно для характеристики случайной величины.
Пусть доходы Х и Y (в долларах) двух фирм заданы распределениями:

Иногда удобно пользоваться другой формулой, которую можно получить, если воспользоваться свойствами математического ожидания,
Дисперсия существует, если ряд (соответственно интеграл) сходится.
Неотрицательное число ![]() называется средним квадратическим отклонением
случайной величины Х.
Оно имеет размерность случайной величины Х
и определяет некоторый стандартный среднеквадратичный интервал рассеивания, симметричный относительно математического ожидания. Величину иногда называют стандартным отклонением.
называется средним квадратическим отклонением
случайной величины Х.
Оно имеет размерность случайной величины Х
и определяет некоторый стандартный среднеквадратичный интервал рассеивания, симметричный относительно математического ожидания. Величину иногда называют стандартным отклонением.
Случайная величина называется центрированной , если . Случайная величина называется нормированной (стандартной), если .
Продолжим пример . Вычислим дисперсию доходов двух фирм:
Сравнивания дисперсии, видим, что доход второй фирмы варьирует больше, чем первой.
Свойства дисперсии .
1. Дисперсия постоянной величины равна нулю, т.е. , если константа. Это очевидно, так как постоянная величина имеет математическое ожидание, равное постоянной величине, т.е. .
2. Постоянный множитель C можно вынести за знак дисперсии, предварительно возведя его в квадрат.
Действительно,
3. Дисперсия алгебраической суммы двух независимых случайных величин равна сумме их дисперсией, т.е.

Выражение называется ковариацией величин Х и Y (см. Тема 4, §2). Для независимых случайных величин ковариация равна нулю, т.е.
Используя это равенство, можно пополнить список свойств математического ожидания. Если случайные величины Х и Y независимы , то математическое ожидание произведения равно произведению математических ожиданий, а именно:
Если случайная величина преобразована линейно, т.е. , то
![]() .
.
Пример 1. Пусть производится n независимых испытаний, вероятность появления события А в каждом из которых постоянна и равна p . Чему равна дисперсия числа появлений события А в этих испытаниях?
Решение. Пусть – число появления события А в первом испытании, – число появления события А во втором испытании и т.д. Тогда общее число наступления события А в n испытаниях равно
Воспользовавшись свойством 3 дисперсии, получим
Здесь мы воспользовались тем, что ![]() , i
= (см. примеры 1 и 2, п.3.3.1.).
, i
= (см. примеры 1 и 2, п.3.3.1.).
Пример 2. Пусть Х – сумма вклада (в долларах) в банке – задана распределением вероятностей
| Х | ||||||
| i = | 0,01 | 0,03 | 0,10 | 0,30 | 0,5 | 0,06 |
Найти среднюю сумму вклада и дисперсию.
Решение. Средняя сумма вклада равна математическому ожиданию
Для вычисления дисперсии воспользуемся формулой
D(X) = 8196 – 7849,96 = 348,04 .
Среднее квадратическое отклонение
Моменты.
Для того, чтобы учесть влияние на математическое ожидание тех возможных значений случайной величины Х , которые велики, но имеют малую вероятность, целесообразно рассматривать математические ожидания целой положительной степени случайной величины.
Математическое ожидание и дисперсия - чаще всего применяемые числовые характеристики случайной величины. Они характеризуют самые важные черты распределения: его положение и степень разбросанности. Во многих задачах практики полная, исчерпывающая характеристика случайной величины - закон распределения - или вообще не может быть получена, или вообще не нужна. В этих случаях ограничиваются приблизительным описанием случайной величины с помощью числовых характеристик.
Математическое ожидание часто называют просто средним значением случайной величины. Дисперсия случайной величины - характеристика рассеивания, разбросанности случайной величины около её математического ожидания.
Математическое ожидание дискретной случайной величины
Подойдём к понятию математического ожидания, сначала исходя из механической интерпретации распределения дискретной случайной величины. Пусть единичная масса распределена между точками оси абсцисс x 1 , x 2 , ..., x n , причём каждая материальная точка имеет соответствующую ей массу из p 1 , p 2 , ..., p n . Требуется выбрать одну точку на оси абсцисс, характеризующую положение всей системы материальных точек, с учётом их масс. Естественно в качестве такой точки взять центр массы системы материальных точек. Это есть среднее взвешенное значение случайной величины X , в которое абсцисса каждой точки x i входит с "весом", равным соответствующей вероятности. Полученное таким образом среднее значение случайной величины X называется её математическим ожиданием.
Математическим ожиданием дискретной случайной величины называется сумма произведений всех возможных её значений на вероятности этих значений:
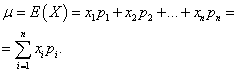
Пример 1. Организована беспроигрышная лотерея. Имеется 1000 выигрышей, из них 400 по 10 руб. 300 - по 20 руб. 200 - по 100 руб. и 100 - по 200 руб. Каков средний размер выигрыша для купившего один билет?
Решение. Средний выигрыш мы найдём, если общую сумму выигрышей, которая равна 10*400 + 20*300 + 100*200 + 200*100 = 50000 руб, разделим на 1000 (общая сумма выигрышей). Тогда получим 50000/1000 = 50 руб. Но выражение для подсчёта среднего выигрыша можно представить и в следующем виде:
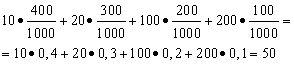
С другой стороны, в данных условиях размер выигрыша является случайной величиной, которая может принимать значения 10, 20, 100 и 200 руб. с вероятностями, равными соответственно 0,4; 0,3; 0,2; 0,1. Следовательно, ожидаемый средний выигрыш равен сумме произведений размеров выигрышей на вероятности их получения.
Пример 2. Издатель решил издать новую книгу. Продавать книгу он собирается за 280 руб., из которых 200 получит он сам, 50 - книжный магазин и 30 - автор. В таблице дана информация о затратах на издание книги и вероятности продажи определённого числа экземпляров книги.
Найти ожидаемую прибыль издателя.
Решение. Случайная величина "прибыль" равна разности доходов от продажи и стоимости затрат. Например, если будет продано 500 экземпляров книги, то доходы от продажи равны 200*500=100000, а затраты на издание 225000 руб. Таким образом, издателю грозит убыток размером в 125000 руб. В следующей таблице обобщены ожидаемые значения случайной величины - прибыли:
| Число | Прибыль x i | Вероятность p i | x i p i |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| Всего: | 1,00 | 25000 |
Таким образом, получаем математическое ожидание прибыли издателя:
![]() .
.
Пример 3. Вероятность попадания при одном выстреле p = 0,2 . Определить расход снарядов, обеспечивающих математическое ожидание числа попаданий, равное 5.
Решение. Из всё той же формулы математического ожидания, которую мы использовали до сих пор, выражаем x - расход снарядов:
![]() .
.
Пример 4. Определить математическое ожидание случайной величины x числа попаданий при трёх выстрелах, если вероятность попадания при каждом выстреле p = 0,4 .
Подсказка: вероятность значений случайной величины найти по формуле Бернулли .
Свойства математического ожидания
Рассмотрим свойства математического ожидания.
Свойство 1. Математическое ожидание постоянной величины равно этой постоянной:
Свойство 2. Постоянный множитель можно выносить за знак математического ожидания:
![]()
Свойство 3. Математическое ожидание суммы (разности) случайных величин равно сумме (разности) их математических ожиданий:
Свойство 4. Математическое ожидание произведения случайных величин равно произведению их математических ожиданий:
Свойство 5. Если все значения случайной величины X уменьшить (увеличить) на одно и то же число С , то её математическое ожидание уменьшится (увеличится) на то же число:
![]()
Когда нельзя ограничиваться только математическим ожиданием
В большинстве случаев только математическое ожидание не может в достаточной степени характеризовать случайную величину.
Пусть случайные величины X и Y заданы следующими законами распределения:
| Значение X | Вероятность |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| Значение Y | Вероятность |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
Математические ожидания этих величин одинаковы - равны нулю:
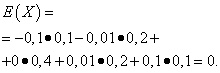
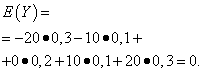
Однако характер распределения их различный. Случайная величина X может принимать только значения, мало отличающиеся от математического ожидания, а случайная величина Y может принимать значения, значительно отклоняющиеся от математического ожидания. Аналогичный пример: средняя заработная плата не даёт возможности судить об удельном весе высоко- и низкооплачиваемых рабочих. Иными словами, по математическому ожиданию нельзя судить о том, какие отклонения от него, хотя бы в среднем, возможны. Для этого нужно найти дисперсию случайной величины.
Дисперсия дискретной случайной величины
Дисперсией дискретной случайной величины X называется математическое ожидание квадрата отклонения её от математического ожидания:
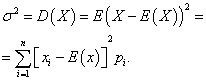
Средним квадратическим отклонением случайной величины X называется арифметическое значение квадратного корня её дисперсии:
![]() .
.
Пример 5. Вычислить дисперсии и средние квадратические отклонения случайных величин X и Y , законы распределения которых приведены в таблицах выше.
Решение. Математические ожидания случайных величин X и Y , как было найдено выше, равны нулю. Согласно формуле дисперсии при Е (х )=Е (y )=0 получаем:

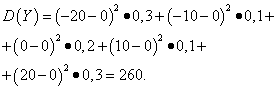
Тогда средние квадратические отклонения случайных величин X и Y составляют
![]() .
.
Таким образом, при одинаковых математических ожиданиях дисперсия случайной величины X очень мала, а случайной величины Y - значительная. Это следствие различия в их распределении.
Пример 6. У инвестора есть 4 альтернативных проекта инвестиций. В таблице обобщены данные об ожидаемой прибыли в этих проектах с соответствующей вероятностью.
| Проект 1 | Проект 2 | Проект 3 | Проект 4 |
| 500, P =1 | 1000, P =0,5 | 500, P =0,5 | 500, P =0,5 |
| 0, P =0,5 | 1000, P =0,25 | 10500, P =0,25 | |
| 0, P =0,25 | 9500, P =0,25 |
Найти для каждой альтернативы математическое ожидание, дисперсию и среднее квадратическое отклонение.
Решение. Покажем, как вычисляются эти величины для 3-й альтернативы:
В таблице обобщены найденные величины для всех альтернатив.
У всех альтернатив одинаковы математические ожидания. Это означает, что в долгосрочном периоде у всех - одинаковые доходы. Стандартное отклонение можно интерпретировать как единицу измерения риска - чем оно больше, тем больше риск инвестиций. Инвестор, который не желает большого риска, выберет проект 1, так как у него наименьшее стандартное отклонение (0). Если же инвестор отдаёт предпочтение риску и большим доходам в короткий период, то он выберет проект наибольшим стандартным отклонением - проект 4.
Свойства дисперсии
Приведём свойства дисперсии.
Свойство 1. Дисперсия постоянной величины равна нулю:
Свойство 2. Постоянный множитель можно выносить за знак дисперсии, возводя его при этом в квадрат:
![]() .
.
Свойство 3. Дисперсия случайной величины равна математическому ожиданию квадрата этой величины, из которого вычтен квадрат математического ожидания самой величины:
![]() ,
,
где ![]() .
.
Свойство 4. Дисперсия суммы (разности) случайных величин равна сумме (разности) их дисперсий:
Пример 7. Известно, что дискретная случайная величина X принимает лишь два значения: −3 и 7. Кроме того, известно математическое ожидание: E (X ) = 4 . Найти дисперсию дискретной случайной величины.
Решение. Обозначим через p вероятность, с которой случайная величина принимает значение x 1 = −3 . Тогда вероятностью значения x 2 = 7 будет 1 − p . Выведем уравнение для математического ожидания:
E (X ) = x 1 p + x 2 (1 − p ) = −3p + 7(1 − p ) = 4 ,
откуда получаем вероятности: p = 0,3 и 1 − p = 0,7 .
Закон распределения случайной величины:
| X | −3 | 7 |
| p | 0,3 | 0,7 |
Дисперсию данной случайной величины вычислим по формуле из свойства 3 дисперсии:
D (X ) = 2,7 + 34,3 − 16 = 21 .
Найти математическое ожидание случайной величины самостоятельно, а затем посмотреть решение
Пример 8. Дискретная случайная величина X принимает лишь два значения. Большее из значений 3 она принимает с вероятностью 0,4. Кроме того, известна дисперсия случайной величины D (X ) = 6 . Найти математическое ожидание случайной величины.
Пример 9. В урне 6 белых и 4 чёрных шара. Из урны вынимают 3 шара. Число белых шаров среди вынутых шаров является дискретной случайной величиной X . Найти математическое ожидание и дисперсию этой случайной величины.
Решение. Случайная величина X может принимать значения 0, 1, 2, 3. Соответствующие им вероятности можно вычислить по правилу умножения вероятностей . Закон распределения случайной величины:
| X | 0 | 1 | 2 | 3 |
| p | 1/30 | 3/10 | 1/2 | 1/6 |
Отсюда математическое ожидание данной случайной величины:
M (X ) = 3/10 + 1 + 1/2 = 1,8 .
Дисперсия данной случайной величины:
D (X ) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
Математическое ожидание и дисперсия непрерывной случайной величины
Для непрерывной случайной величины механическая интерпретация математического ожидания сохранит тот же смысл: центр массы для единичной массы, распределённой непрерывно на оси абсцисс с плотностью f (x ). В отличие от дискретной случайной величиной, у которой аргумент функции x i изменяется скачкообразно, у непрерывной случайной величины аргумент меняется непрерывно. Но математическое ожидание непрерывной случайной величины также связано с её средним значением.
Чтобы находить математическое ожидание и дисперсию непрерывной случайной величины, нужно находить определённые интегралы . Если дана функция плотности непрерывной случайной величины, то она непосредственно входит в подынтегральное выражение. Если дана функция распределения вероятностей, то, дифференцируя её, нужно найти функцию плотности.
Арифметическое среднее всех возможных значений непрерывной случайной величины называется её математическим ожиданием , обозначаемым или .
В предыдущем мы привели ряд формул, позволяющих находить числовые характеристики функций, когда известны законы распределения аргументов. Однако во многих случаях для нахождения числовых характеристик функций не требуется знать даже законов распределения аргументов, а достаточно знать только некоторые их числовые характеристики; при этом мы вообще обходимся без каких бы то ни было законов распределения. Определение числовых характеристик функций по заданным числовым характеристикам аргументов широко применяется в теории вероятностей и позволяет значительно упрощать решение ряда задач. По преимуществу такие упрощенные методы относятся к линейным функциям; однако некоторые элементарные нелинейные функции также допускают подобный подход.
В настоящем мы изложим ряд теорем о числовых характеристиках функций, представляющих в своей совокупности весьма простой аппарат вычисления этих характеристик, применимый в широком круге условий.
1. Математическое ожидание неслучайной величины
Сформулированное свойство является достаточно очевидным; доказать его можно, рассматривая неслучайную величину как частный вид случайной, при одном возможном значении с вероятностью единица; тогда по общей формуле для математического ожидания:
![]() .
.
2. Дисперсия неслучайной величины
Если - неслучайная величина, то
3. Вынесение неслучайной величины за знак математического ожидания
![]() , (10.2.1)
, (10.2.1)
т. е. неслучайную величину можно выносить за знак математического ожидания.
Доказательство.
а) Для прерывных величин
б) Для непрерывных величин
 .
.
4. Вынесение неслучайной величины за знак дисперсии и среднего квадратического отклонения
Если - неслучайная величина, а - случайная, то
![]() , (10.2.2)
, (10.2.2)
т. е. неслучайную величину можно выносить за знак дисперсии, возводя ее в квадрат.
Доказательство. По определению дисперсии
Следствие
![]() ,
,
т. е. неслучайную величину можно выносить за знак среднего квадратического отклонения ее абсолютным значением. Доказательство получим, извлекая корень квадратный из формулы (10.2.2) и учитывая, что с.к.о. - существенно положительная величина.
5. Математическое ожидание суммы случайных величин
Докажем, что для любых двух случайных величин и
т. е. математическое ожидание суммы двух случайных величин равно сумме их математических ожиданий.
Это свойство известно под названием теоремы сложения математических ожиданий.
Доказательство.
а) Пусть - система прерывных случайных величин. Применим к сумме случайных величин общую формулу (10.1.6) для математического ожидания функции двух аргументов:
![]() .
.
Ho представляет собой не что иное, как полную вероятность того, что величина примет значение :
![]() ;
;
следовательно,
![]() .
.
Аналогично докажем, что
![]() ,
,
и теорема доказана.
б) Пусть - система непрерывных случайных величин. По формуле (10.1.7)

 . (10.2.4)
. (10.2.4)
Преобразуем первый из интегралов (10.2.4):

 ;
;
аналогично
 ,
,
и теорема доказана.
Следует специально отметить, что теорема сложения математических ожиданий справедлива для любых случайных величин - как зависимых, так и независимых.
Теорема сложения математических ожиданий обобщается на произвольное число слагаемых:
 , (10.2.5)
, (10.2.5)
т. е. математическое ожидание суммы нескольких случайных величин равно сумме их математических ожиданий.
Для доказательства достаточно применить метод полной индукции.
6. Математическое ожидание линейной функции
Рассмотрим линейную функцию нескольких случайных аргументов :
где - неслучайные коэффициенты. Докажем, что
 , (10.2.6)
, (10.2.6)
т. е. математическое ожидание линейной функции равно той же линейной функции от математических ожиданий аргументов.
Доказательство. Пользуясь теоремой сложения м. о. и правилом вынесения неслучайной величины за знак м. о., получим:

 .
.
7. Дисп ep сия суммы случайных величин
Дисперсия суммы двух случайных величин равна сумме их дисперсий плюс удвоенный корреляционный момент:
Доказательство. Обозначим
По теореме сложения математических ожиданий
Перейдем от случайных величин к соответствующим центрированным величинам . Вычитая почленно из равенства (10.2.8) равенство (10.2.9), имеем:
По определению дисперсии
![]()
что и требовалось доказать.
Формула (10.2.7) для дисперсии суммы может быть обобщена на любое число слагаемых:
 ,
(10.2.10)
,
(10.2.10)
где
-
корреляционный момент величин , знак под суммой обозначает, что суммирование
распространяется на все возможные попарные сочетания случайных величин ![]() .
.
Доказательство аналогично предыдущему и вытекает из формулы для квадрата многочлена.
Формула (10.2.10) может быть записана еще в другом виде:
 , (10.2.11)
, (10.2.11)
где
двойная сумма распространяется на все элементы корреляционной матрицы системы
величин ![]() ,
содержащей как корреляционные моменты, так и дисперсии.
,
содержащей как корреляционные моменты, так и дисперсии.
Если все случайные величины ![]() , входящие в систему,
некоррелированы (т. е. при ), формула (10.2.10) принимает вид:
, входящие в систему,
некоррелированы (т. е. при ), формула (10.2.10) принимает вид:
 , (10.2.12)
, (10.2.12)
т. е. дисперсия суммы некоррелированных случайных величин равна сумме дисперсий слагаемых.
Это положение известно под названием теоремы сложения дисперсий.
8. Дисперсия линейной функции
Рассмотрим линейную функцию нескольких случайных величин.
где - неслучайные величины.
Докажем, что дисперсия этой линейной функции выражается формулой
 , (10.2.13)
, (10.2.13)
где - корреляционный момент величин , .
Доказательство. Введем обозначение:
 . (10.2.14)
. (10.2.14)
Применяя к правой части выражения (10.2.14) формулу (10.2.10) для дисперсии суммы и учитывая, что , получим:
где - корреляционный момент величин :
![]() .
.
Вычислим этот момент. Имеем:
![]() ;
;
аналогично
Подставляя это выражение в (10.2.15), приходим к формуле (10.2.13).
В частном случае, когда все
величины ![]() некоррелированны,
формула (10.2.13) принимает вид:
некоррелированны,
формула (10.2.13) принимает вид:
 , (10.2.16)
, (10.2.16)
т. е. дисперсия линейной функции некоррелированных случайных величин равна сумме произведений квадратов коэффициентов на дисперсии соответствующих аргументов.
9. Математическое ожидание произведения случайных величин
Математическое ожидание произведения двух случайных величин равно произведению их математических ожиданий плюс корреляционный момент:
Доказательство. Будем исходить из определения корреляционного момента:
Преобразуем это выражение, пользуясь свойствами математического ожидания:
что, очевидно, равносильно формуле (10.2.17).
Если случайные величины некоррелированны , то формула (10.2.17) принимает вид:
т. е. математическое ожидание произведения двух некоррелированных случайных величин равно произведению их математических ожиданий.
Это положение известно под названием теоремы умножения математических ожиданий.
Формула (10.2.17) представляет собой не что иное, как выражение второго смешанного центрального момента системы через второй смешанный начальный момент и математические ожидания:
![]() . (10.2.19)
. (10.2.19)
Это выражение часто применяется на практике при вычислении корреляционного момента аналогично тому, как для одной случайной величины дисперсия часто вычисляется через второй начальный момент и математическое ожидание.
Теорема умножения математических ожиданий обобщается и на произвольное число сомножителей, только в этом случае для ее применения недостаточно того, чтобы величины были некоррелированны, а требуется, чтобы обращались в нуль и некоторые высшие смешанные моменты, число которых зависит от числа членов в произведении. Эти условия заведомо выполнены при независимости случайных величин, входящих в произведение. В этом случае
 , (10.2.20)
, (10.2.20)
т. е. математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий.
Это положение легко доказывается методом полной индукции.
10. Дисперсия произведения независимых случайных величин
Докажем, что для независимых величин
Доказательство. Обозначим . По определению дисперсии
Так как величины независимы, и
При независимых величины тоже независимы; следовательно,
,
![]()
Но есть не что иное, как второй начальный момент величины , и, следовательно, выражается через дисперсию:
![]() ;
;
аналогично
![]() .
.
Подставляя эти выражения в формулу (10.2.22) и приводя подобные члены, приходим к формуле (10.2.21).
В случае, когда перемножаются центрированные случайные величины (величины с математическими ожиданиями, равными нулю), формула (10.2.21) принимает вид:
![]() , (10.2.23)
, (10.2.23)
т. е. дисперсия произведения независимых центрированных случайных величин равна произведению их дисперсий.
11. Высшие моменты суммы случайных величин
В некоторых случаях приходится вычислять высшие моменты суммы независимых случайных величин. Докажем некоторые относящиеся сюда соотношения.
1) Если величины независимы, то
Доказательство.
откуда по теореме умножения математических ожиданий
Но первый центральный момент для любой величины равен нулю; два средних члена обращаются в нуль, и формула (10.2.24) доказана.
Соотношение (10.2.24) методом индукции легко обобщается на произвольное число независимых слагаемых:
 . (10.2.25)
. (10.2.25)
2) Четвертый центральный момент суммы двух независимых случайных величин выражается формулой
где - дисперсии величин и .
Доказательство совершенно аналогично предыдущему.
Методом полной индукции легко доказать обобщение формулы (10.2.26) на произвольное число независимых слагаемых.
Дисперсией (рассеянием) дискретной случайной величины D(X) называют математическое ожидание квадрата отклонения случайной величины от ее математического ожидания
1 свойство . Дисперсия постоянной величины C равна нулю; D(C) = 0.
Доказательство. По определению дисперсии, D(C) = M{ 2 }.
Из первого свойства математического ожидания D(C) = M[(C – C) 2 ] = M(0) = 0.
2 свойство. Постоянный множитель можно выносить за знак дисперсии, возводя его в квадрат:
D(CX) = C 2 D(X)
Доказательство. По определению дисперсии, D(CX) = M{ 2 }
Из второго свойства математического ожидания D(CX)=M{ 2 }= C 2 M{ 2 }=C 2 D(X)
3 свойство. Дисперсия суммы двух независимых случайных величин равна сумме дисперсий этих величин:
D = D[X] + D.
Доказательство. По формуле для вычисления дисперсии имеем
D(X + Y) = M[(X + Y) 2 ] − 2
Раскрыв скобки и пользуясь свойствами математического ожидания суммы нескольких величин и произведения двух независимых случайных величин, получим
D(X + Y) = M − 2 = M(X2) + 2M(X)M(Y) + M(Y2) − M2(X) − 2M(X)M(Y) − M2(Y) = {M(X2) − 2}+{M(Y2) − 2} = D(X) + D(Y). Итак, D(X + Y) = D(X) + D(Y)
4 свойство . Дисперсия разности двух независимых случайных величин равна сумме их дисперсий:
D(X − Y) = D(X) + D(Y)
Доказательство. В силу третьего свойства D(X − Y) = D(X) + D(–Y). По второму свойству
D(X − Y) = D(X) + (–1) 2 D(Y) или D(X − Y) = D(X) + D(Y)
Числовые характеристики систем случайных величин. Коэффициент корреляции, свойства коэффициента корреляции.
Корреляционный момент. Характеристикой зависимости между случайными величинами и служит математическое ожидание произведения отклонений и от их центров распределений (так иногда называют математическое ожидание случайной величины), которое называется корреляционным моментом или ковариацией:
Для вычисления корреляционного момента дискретных величин используют формулу:
а для непрерывных величин – формулу:
Коэффициентом корреляции
rxy случайных величин X и Y называют отношение корреляционного момента к произведению среднеквадратичных отклонений величин:
- коэффициент корреляции;
Свойства коэффициента корреляции:
1. Если Х и У независимые случайные величины, то r =0;
2. -1≤ r ≤1 .При этом, если |r| =1, то между Х и У функциональная, а именно линейная зависимость;
3. r характеризует относительную величину отклонения М(ХУ) от М(Х)М(У), и т.к. отклонение имеет место только для зависимых величин, то rхарактеризует тесноту зависимости.
Линейная функция регрессии.
Рассмотрим двумерную случайную величину (X, Y), где X и У - зависимые случайные величины. Представим одну из величин как функцию другой. Ограничимся приближенным представлением (точное приближение, вообще говоря, невозможно) величины Y в виде линейной функции величины X:
![]() где α и β - параметры, подлежащие определению.
где α и β - параметры, подлежащие определению.
Теорема. Линейная средняя квадратическая регрессия Y на X имеет вид
![]() где
m x =M(X), m y =M(Y), σ x =√D(X), σ y =√D(Y), r=µ xy /(σ x σ y)-коэффициент корреляции величин X и Y.
где
m x =M(X), m y =M(Y), σ x =√D(X), σ y =√D(Y), r=µ xy /(σ x σ y)-коэффициент корреляции величин X и Y.
Коэффициент β=rσ y /σ x называют коэффициентом регрессии Y на X, а прямую
![]() называют прямой среднеквадратической регрессии
Y на X.
называют прямой среднеквадратической регрессии
Y на X.
Неравенство Маркова.
Формулировка неравенства Маркова
Если среди значений случайной величины Х нет отрицательных, то вероятность того, что она примет какое-нибудь значение, превосходящее положительное число А, не больше дроби , т.е.
а вероятность того, что она примет какое-нибудь значение, не превосходящее положительного числа А, не меньше , т.е.
Неравенство Чебышева.
Неравенство Чебышева . Вероятность того, что отклонение случайной величины X от ее математического ожидания по абсолютной величине меньше положительного числа ε, не меньше, чем 1 −D[X]ε 2
P(|X – M(X)| < ε) ≥ 1 –D(X)ε 2
Доказательство. Так как события, состоящие в осуществлении неравенств
P(|X−M(X)| < ε) и P(|X – M(X)| ≥ε) противоположны, то сумма их вероятностей равна единице, т. е.
P(|X – M(X)| < ε) + P(|X – M(X)| ≥ ε) = 1.
Отсюда интересующая нас вероятность
P(|X – M(X)| < ε) = 1 − P(|X – M(X)| > ε).
Таким образом, задача сводится к вычислению вероятности P(|X –M(X)| ≥ ε).
Напишем выражение для дисперсии случайной величины X
D(X) = 2 p1 + 2 p 2 + . . . + 2 p n
Все слагаемые этой суммы неотрицательны. Отбросим те слагаемые, у которых |x i – M(X)| < ε (для оставшихся слагаемых |x j – M(X)| ≥ ε), вследствие чего сумма может только уменьшиться. Условимся считать для определенности, что отброшено k первых слагаемых (не нарушая общности, можно считать, что в таблице распределения возможные значения занумерованы именно в таком порядке). Таким образом,
D(X) ≥ 2 p k+1 + 2 p k+2 + . . . + 2 p n
Обе части неравенства |x j –M(X)| ≥ ε (j = k+1, k+2, . . ., n) положительны, поэтому, возведя их в квадрат, получим равносильное неравенство |x j – M(X)| 2 ≥ε 2 .Заменяя в оставшейся сумме каждый из множителей
|x j – M(X)| 2 числом ε 2 (при этом неравенство может лишь усилиться), получим
D(X) ≥ ε 2 (p k+1 + p k+2 + . . . + p n)
По теореме сложения, сумма вероятностей p k+1 +p k+2 +. . .+p n есть вероятность того, что X примет одно, безразлично какое, из значений x k+1 +x k+2 +. . .+x n , а при любом из них отклонение удовлетворяет неравенству |x j – M(X)| ≥ ε. Отсюда следует, что сумма p k+1 + p k+2 + . . . + p n выражает вероятность
P(|X – M(X)| ≥ ε).
Это позволяет переписать неравенство для D(X) так
D(X) ≥ ε 2 P(|X – M(X)| ≥ ε)
P(|X – M(X)|≥ ε) ≤D(X)/ε 2
Окончательно получим
P(|X – M(X)| < ε) ≥D(X)/ε 2
Теорема Чебышева.
Теорема Чебышева . Если - попарно независимые случайные величины, причем дисперсии их равномерно ограничены (не превышают постоянного числа С), то, как бы мало ни было положительное число ε, вероятность неравенства
будет как угодно близка к единице, если число случайных величин достаточно велико.
Другими словами, в условиях теоремы
Доказательство . Введем в рассмотрение новую случайную величину - среднее арифметическое случайных величин
![]()
Найдем математическое ожидание Х. Пользуясь свойствами математического ожидания (постоянный множитель можно вынести за знак математического ожидания, математическое ожидание суммы равно сумме математических ожиданий слагаемых), получим
| (1) |
Применяя к величине Х неравенство Чебышева, имеем
![]()
или, учитывая соотношение (1)
![]()
Пользуясь свойствами дисперсии (постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат; дисперсия суммы независимых случайных величин равна сумме дисперсий слагаемых), получим
По условию дисперсии всех случайных величин ограничены постоянным числом С, т.е. имеют место неравенства:
| |
Подставляя правую часть (2) в неравенство (1) (отчего последнее может быть лишь усилено), имеем
Отсюда, переходя к пределу при n→∞, получим
Наконец, учитывая, что вероятность не может превышать единицу, окончательно можем написать
Теорема доказана.
Теорема Бернулли.
Теорема Бернулли . Если в каждом из n независимых испытаний вероятность p появления события A постоянна, то как угодно близка к единице вероятность того, что отклонение относительной частоты от вероятности p по абсолютной величине будет сколь угодно малым, если число испытаний достаточно велико.
Другими словами, если ε - сколь угодно малое положительное число, то при соблюдении условий теоремы имеет место равенство
![]()
Доказательство . Обозначим через X 1 дискретную случайную величину - число появлений события в первом испытании, через X 2 - во втором, ..., X n - в n -м испытании. Ясно, что каждая из величин может принять лишь два значения: 1 (событие A наступило) с вероятностью p и 0 (событие не появилось) с вероятностью .
Однако на этом тема не заканчивается. У дисперсии есть различные полезные свойства, с которыми мы и познакомимся в данной заметке.
Дисперсия используется в самых разных формулах и методах анализа. Чтобы хорошо понимать глубинный смысл тех или иных формул, очень неплохо знать, как они образованы. Тогда и анализ данных будет гораздо интереснее и понятнее.
Итак, формула дисперсии имеет следующий вид:
Обозначения прежние:
D – дисперсия,
x – анализируемый показатель, с чертой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
Собственно, этот вид формулы напрямую отражает ее суть – средний квадрат отклонений. Но что здесь полезно отметить. В те времена, когда люди еще не имели ПЭВМ, расчеты приходилось делать на листе бумаги или в уме. Дело, конечно, полезное – мозги развивает, но не сильно способствует скорости и точности. Тем не менее, и сегодня можно столкнуться с необходимостью ручных расчетов и манипуляцией с формулой. В этом случае формулу дисперсии удобно представить в другом виде:
То есть как разницу между средним квадратом и квадратом средней исходных значений. Здесь нет непосредственно отклонений от средней арифметической, что делает формулу значительно проще. Убедимся, что обе формулы расчета дисперсии идентичны. Для этого запишем еще раз первоначальный вид.
Теперь, раскроем скобки.
![]()
Т.к. средняя арифметическая для заданного набора данных является величиной постоянной, то для удвоенного произведения можно применить :
![]()
Разделим каждое слагаемое числителя на n .
Последний штрих.
Все сошлось.
Предлагаю запомнить такую форму записи. Обязательно пригодиться.
В предыдущих публикациях ничего не было сказано о том, что по аналогии со средней арифметической дисперсия может быть простой и взвешенной. До сих пор мы рассматривали только простую дисперсию. Но если исходные данные сгруппированы, то веса нужны не только для расчета , но и для расчета дисперсии:
![]()
где f –веса (количество значений в группе).
Извлекая квадратный корень, получим взвешенное среднеквадратическое отклонение. Как и со средней арифметической, простую дисперсию можно считать частным случаем взвешенной, когда все веса равны единице.
Ничего сложного здесь нет – в числителе по-прежнему берется сумма всех отклонений, а не только уникальных, а в знаменателе – количество всех наблюдений, даже тех, которые повторяются.
Малоопытному аналитику часто трудно осознать, как наглядно представить дисперсию. Вот средняя – понятно, что-то в середине. Например, центр масс на рисунке из предыдущей статьи. На этом же рисунке можно рассмотреть и физический смысл дисперсии. Напомню, что мы берем спицу с нанизанными грузиками. Среднее арифметическое из расстояний от начала спицы до каждого из грузиков будет соответствовать точке равновесия. Однако есть еще одна важная физическая характеристика такой системы – момент инерции.
Наподобие того, как масса тела характеризует его инертность в поступательном движении, момент инерции имеет похожий смысл во вращательном движении. Например, автомобиль из-за своей массы (инертности) не может остановиться мгновенно (разве что во время краш-теста). Точно так трудно мгновенно остановить качели с людьми (типа лодочка в парке культуры и отдыха). Случай с автомобилем – поступательное движение, с качелями – вращательное. В отличие от инерции в поступательном движении момент инерции зависит не только от массы, но еще и от расстояния массы до точки вращения. Чем дальше тело от точки вращения, тем большим моментом инерции оно обладает. Длинное топорище позволят рубить дерево гораздо эффективнее, чем короткое. Вернемся к нашей картинке с грузиками на спице и добавим в нее несколько пояснений.

В такой системе момент инерции равен сумме произведений квадратов расстояний каждого грузика до точки равновесия и соответствующих масс. Формула момента инерции имеет следующий вид:
![]()
где m – масса отдельного грузика
Нетрудно заметить, расстояние грузиков до центра является одновременно и отклонением от средней. Масса грузиков в этом случае соответствует весу отклонения (в статистическом смысле). Отсюда легко увидеть, что момент инерции уравновешенной системы – это числитель дисперсии расстояний грузиков до центра масс. Чем дальше грузики от центра, тем больше момент инерции и, соответственно, дисперсия.
Свойства дисперсии
Как я уже не раз упоминал, сама по себе дисперсия – показатель малоинформативный. Дисперсию всегда с чем-то сравнивают и используются в других формулах. Отсюда очень важно знать ее математические свойства. Нижеследующее рекомендую прочитать вдумчиво и по возможности запомнить.
Для большей наглядности обозначим дисперсию как D(X) .
Свойство 1 . Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0 .
Оно и не удивительно – у постоянной величины нет отклонений.
Свойство 2 . Если случайную величину умножить на постоянную А , то дисперсия этой случайной величины увеличится в А 2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А 2 D(X) .
Данное свойство вполне очевидно, если вспомнить, что при расчете дисперсии отклонения от средней возводятся в квадрат.
Свойство 3 . Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A+X) = D(X) .
Это свойство также вполне понятно, т.к. все значения и их среднее увеличиваются на одну и ту же величину, и при взятии их разностей, величина А просто сокращается.
Свойство 4 . Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y) .
Учитывая второй способ расчета дисперсии (см. выше), а также математического ожидания, выводится довольно просто:
D(X+Y) = M(X+Y) 2 — (M(X+Y)) 2 = M(X) 2 + 2M(XY) + M(Y) 2 — (M(X)) 2 — 2M(XY) — (M(Y)) 2 =
= M(X) 2 — (M(X)) 2 + M(Y) 2 — (M(Y)) 2 = D(X) + D(Y) . Ч. т. д.
Свойство 5 . Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y) .
Здесь учитывается то, что дисперсия всегда положительна (все отклонения от средней возводятся в квадрат).
На этой радостной ноте и закончим заметку.
Всех благ. Приходите еще и приводите своих друзей.



