Вариационный ряд состоит. V
Ряды, построенные по количественному признаку , называются вариационным .
Ряды распределений состоят из вариантов (значений признака) и частот (численности групп). Частоты, выраженные в виде относительных величин (долей, процентов) называются частостями . Сумма всех частот называется объёмом ряда распределения.
По виду ряды распределения делятся на дискретные (построены по прерывным значениям признака) и интервальные (построены на непрерывных значениях признака).
Вариационный ряд представляет собой две колонки (или строки); в одной из которых приводятся отдельные значения варьирующего признака, именуемые вариантами и обозначаемые Х; а в другой – абсолютные числа, показывающие сколько раз (как часто) встречается каждый вариант. Показатели второй колонки называются частотами и условно обозначают через f. Еще раз заметим, что во второй колонке могут использоваться и относительные показатели, характеризующие долю частоты отдельных вариантов в общей сумме частот. Эти относительные показатели именуются частостями и условно обозначают через ω Сумма всех частостей в этом случае равна единице. Однако частоты можно выражать и в процентах, и тогда сумма всех частостей дает 100%.
Если варианты вариационного ряда выражены в виде дискретных величин, то такой вариационный ряд именуют дискретным.
Для непрерывных признаков вариационные ряды строятся как интервальные , то есть значения признака в них выражаются «от… до …». При этом минимальны значения признака в таком интервале именуют нижней границей интервала, а максимальное – верхней границей.
Интервальные вариационные ряды строят и для дискретных признаков, варьирующих в большом диапазоне. Интервальные ряды могут быть с равными и неравными интервалами.
Рассмотрим как определяется величина равных интервалов. Введем следующие обозначения:
i – величина интервала;
- максимальное значение признака у единиц совокупности;
– минимальное значение признака у единиц совокупности;
n – число выделяемых групп.
, если n известно.
Если число выделяемых групп трудно заранее определить, то для расчета оптимальной величины интервала при достаточном объеме совокупности может быть рекомендована формула, предложенная Стерджессом в 1926 году:
n = 1+ 3.322 lg N, где N – число единиц в совокупности.
Величина неравных интервалов определяется в каждом отдельном случае с учетом особенностей объекта изучения.
Статистическим распределением выборки называют перечень вариант и соответствующих им частот (или относительных частот).
Статистическое распределение выборки можно задать в виде таблицы, в первой графе которой располагаются варианты, а во второй - соответствующие этим вариантам частоты ni , или относительные частоты Pi .
Статистическое распределение выборки
Интервальными называются вариационные ряды, в которых значения признаков, положенных в основу их образования, выражены в определенных пределах (интервалах). Частоты в этом случае относятся, не к отдельным значениям признака, а ко всему интервалу.
Интервальные ряды распределения строятся по непрерывным количественным признакам, а также по дискретным признакам, варьирующим в значительных пределах.
Интервальный ряд можно представить статистическим распределением выборки с указанием интервалов и соответствующих им частот. При этом в качестве частоты интервала принимают сумму частот вариант, попавших в этот интервал.
При группировке по количественным непрерывным признакам важное значение имеет определение размера интервала.
Кроме выборочной средней и выборочной дисперсии применяются и другие характеристики вариационного ряда.
Модой называют варианту, которая имеет наибольшую частоту.
Вариационный ряд – ряд, в котором сопоставлены (по степени возрастания или убывания) варианты и соответствующие им частоты
Варианты – отдельные количественные выражения признака. Обозначаются латинской буквой V . Классическое понимание термина "варианта" предполагает, что вариантой называется каждое уникальное значение признака, без учета количества повторов.
Например, в вариационном ряду показателей систолического артериального давления, измеренного у десяти пациентов:
110, 120, 120, 130, 130, 130, 140, 140, 160, 170;
вариантами являются только 6 значений:
110, 120, 130, 140, 160, 170.
Частота – число, показывающее, сколько раз повторяется варианта. Обозначается латинской буквой P . Сумма всех частот (которая, разумеется, равна числу всех исследуемых) обозначается как n .
- В нашем примере частоты будут принимать следующие значения:
- для варианты 110 частота Р = 1 (значение 110 встречается у одного пациента),
- для варианты 120 частота Р = 2 (значение 120 встречается у двух пациентов),
- для варианты 130 частота Р = 3 (значение 130 встречается у трех пациентов),
- для варианты 140 частота Р = 2 (значение 140 встречается у двух пациентов),
- для варианты 160 частота Р = 1 (значение 160 встречается у одного пациента),
- для варианты 170 частота Р = 1 (значение 170 встречается у одного пациента),
Виды вариационных рядов:
- простой - это ряд, в котором каждая варианта встречается только по одному разу (все частоты при этом равны 1);
- взвешенный - ряд, в котором одна или несколько вариант встречаются неоднократно.
Вариационный ряд служит для описания больших массивов чисел, именно в этой форме изначально представляются собранные данные большинства медицинских исследований. Для того, чтобы охарактеризовать вариационный ряд, рассчитываются специальные показатели, в том числе средние величины, показатели вариабельности (так называемой, дисперсии), показатели репрезентативности выборочных данных.
Показатели вариационного ряда
1) Средняя арифметическая - это обобщающий показатель, характеризующий размер изучаемого признака. Средняя арифметическая обозначается как M , представляет собой самый распространенный вид средней. Средняя арифметическая рассчитывается как отношение суммы значений показателей всех единиц наблюдения к числу всех исследуемых. Методика расчета средней арифметической различается для простого и взвешенного вариационного ряда.
Формула для расчета простой средней арифметической:
Формула для расчета взвешенной средней арифметической:
M = Σ(V * P)/ n
2) Мода – еще одна средняя величина вариационного ряда, соответствующая наиболее часто повторяющейся варианте. Или, если выразиться по другому, это варианта, которой соответствует наибольшая частота. Обозначается как Мо . Мода рассчитывается только для взвешенных рядов, так как в простых рядах ни одна из вариант не повторяется и все частоты равны единице.
Например, в вариационном ряду значений частоты сердечных сокращений:
80, 84, 84, 86, 86, 86, 90, 94;
значение моды составляет 86, так как данная варианта встречается 3 раза, следовательно ее частота - наибольшая.
3) Медиана – значение варианты, делящей вариационный ряд пополам: по обе стороны от нее находится равное число вариант. Медиана также, как и средняя арифметическая и мода, относится к средним величинам. Обозначается как Me
4) Среднее квадратическое отклонение (синонимы: стандартное отклонение, сигмальное отклонение, сигма) - мера вариабельности вариационного ряда. Является интегральным показателем, объединяющим все случаи отклонения вариант от средней. Фактически, отвечает на вопрос: насколько далеко и как часто варианты распространяются от средней арифметической. Обозначается греческой буквой σ ("сигма") .
При численности совокупности более 30 единиц, стандартное отклонение рассчитывается по следующей формуле:
Для малых совокупностей - 30 единиц наблюдения и менее - стандартное отклонение рассчитывается по другой формуле:
Вариационный ряд – это ряд числовых значений признака.
Основные характеристики вариационного ряда: v – варианта, р – частота ее встречаемости.
Виды вариационного ряда:
по частоте встречаемости варианты: простой – варианта встречается один раз, взвешенный – варианта встречается два и более раз;
по расположению варианты: ранжированный – варианты расположены в порядке убывания и возрастания, неранжированный – варианты записаны без определенного порядка;
по объединению вариант в группы: сгруппированный – варианты объединены в группы, несгруппированный – варианты необъединены в группы;
по величине варианты: непрерывный – варианты выражены целым и дробным числом, дискретный – варианты выражены целым числом, сложный – варианты представлены относительной или средней величиной.
Вариационный ряд составляется и оформляется с целью расчета средних величин.
Форма записи вариационного ряда:
8. Средние величины, виды, методика расчета, применение в здравоохранении
Средние величины – совокупная обобщающая характеристика количественных признаков. Применение средних величин :
1. Для характеристики организации работы лечебно-профилактических учреждений и оценки их деятельности:
а) в поликлинике: показатели нагрузки врачей, среднее число посещений, среднее число жителей на участке;
б) в стационаре: среднее число дней работы койки в году; средняя длительность пребывания в стационаре;
в) в центре гигиены, эпидемиологии и общественного здоровья: средняя площадь (или кубатура) на 1 человека, средние нормы питания (белки, жиры, углеводы, витамины, минеральные соли, калории), санитарные нормы и нормативы и т.д.;
2. Для характеристики физического развития (основных антропометрических признаков морфологических и функциональных);
3. Для определения медико-физиологических показателей организма в норме и патологии в клинических и экспериментальных исследованиях.
4. В специальных научных исследованиях.
Отличие средних величин от показателей:
1. Коэффициенты характеризуют альтернативный признак, встречающийся только у некоторой части статистического коллектива, который может иметь место или не иметь место.
Средние величины охватывают признаки, присущие всем членам коллектива, но в разной степени (вес, рост, дни лечения в больнице).
2. Коэффициенты применяются для измерения качественных признаков. Средние величины – для варьирующих количественных признаков.
Виды средних величин:
средняя арифметическая, ее характеристики – среднее квадратическое отклонение и средняя ошибка
мода и медиана. Мода (Мо) – соответствует величине признака, который чаще других встречается в данной совокупности. Медиана (Ме) – величина признака, занимающая срединное значение в данной совокупности. Она делит ряд на 2 равные части по числу наблюдений. Средняя арифметическая величина (М) – в отличие от моды и медианы опирается на все произведенные наблюдения, поэтому является важной характеристикой для всего распределения.
другие виды средних величин, которые применяются в специальных исследованиях: средняя квадратическая, кубическая, гармоническая, геометрическая, прогрессивная.
Средняя арифметическая характеризует средний уровень статистической совокупности.
Для простого ряда, где
∑v – сумма вариант,
n – число наблюдений.
 для взвешенного
ряда, где
для взвешенного
ряда, где
∑vр – сумма произведений каждой варианты на частоту ее встречаемости
n – число наблюдений.
Среднее квадратическое отклонение средней арифметической или сигма (σ) характеризует разнообразие признака
 - для простого ряда
- для простого ряда
Σd 2 – сумма квадратов разности средней арифметической и каждой варианты (d = │M-V│)
n – число наблюдений
 - для взвешенная
ряда
- для взвешенная
ряда
∑d 2 p – сумма произведений квадратов разности средней арифметической и каждой варианты на частоту ее встречаемости,
n – число наблюдений.
О
степени разнообразия можно судить по
величине коэффициента вариации
 .
Более 20% - сильное разнообразие, 10-20% -
среднее разнообразие, менее 10% - слабое
разнообразие.
.
Более 20% - сильное разнообразие, 10-20% -
среднее разнообразие, менее 10% - слабое
разнообразие.
Если к средней арифметической величине прибавить и отнять от нее одну сигму (М ± 1σ), то при нормальном распределении в этих пределах будет находиться не менее 68,3% всех вариант (наблюдений), что считается нормой для изучаемого явления. Если к 2 ± 2σ, то в этих пределах будет находиться 95,5% всех наблюдений, а если к М ± 3σ, то в этих пределах будет находиться 99,7% всех наблюдений. Таким образом, среднее квадратическое отклонение является стандартным отклонением, позволяющим предвидеть вероятность появления такого значения изучаемого признака, которое находится в пределах заданных границ.
Средняя ошибка средней арифметической или ошибка репрезентативности. Для простого, взвешенного рядов и по правилу моментов:
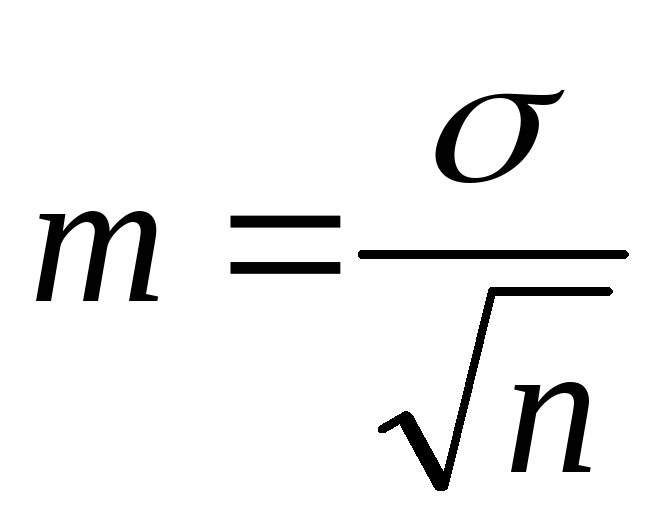 .
.
Для расчета средних величин необходимо: однородность материала, достаточное число наблюдений. Если число наблюдений меньше 30, в формулах расчета σ и m используют n-1.
При оценке полученного результата по размеру средней ошибки пользуются доверительным коэффициентом, которые дает возможность определить вероятность правильного ответа, то есть он указывает на то, что полученная величина ошибки выборки будет не больше действительной ошибки, допущенной вследствие сплошного наблюдения. Следовательно, с увеличением доверительной вероятности увеличивается ширина доверительного интервала, что, в свою очередь повышает доверительность суждения, опорность полученного результата.
Особое место в статистическом анализе принадлежит определению среднего уровня изучаемого признака или явления. Средний уровень признака измеряют средними величинами.
Средняя величина характеризует общий количественный уровень изучаемого признака и является групповым свойством статистической совокупности. Она нивелирует, ослабляет случайные отклонения индивидуальных наблюдений в ту или иную сторону и выдвигает на первый план основное, типичное свойство изучаемого признака.
Средние величины широко используются:
1. Для оценки состояния здоровья населения: характеристики физического развития (рост, вес, окружность грудной клетки и пр.), выявления распространенности и длительности различных заболеваний, анализа демографических показателей (естественного движения населения, средней продолжительности предстоящей жизни, воспроизводства населения, средней численности населения и др.).
2. Для изучения деятельности лечебно-профилактических учреждений, медицинских кадров и оценки качества их работы, планирования и определения потребности населения в различных видах медицинской помощи (среднее число обращений или посещений на одного жителя в год, средняя длительность пребывания больного в стационаре, средняя продолжительность обследования больного, средняя обеспеченность врачами, койками и пр.).
3. Для характеристики санитарно-эпидемиологического состояния (средняя запыленность воздуха в цехе, средняя площадь на одного человека, средние нормы потребления белков, жиров и углеводов и т. д.).
4. Для определения медико-физиологических показателей в норме и патологии, при обработке лабораторных данных, для установления достоверности результатов выборочного исследования в социально-гигиенических, клинических, экспериментальных исследованиях.
Вычисление средних величин выполняется на основе вариационных рядов. Вариационный ряд – это однородная в качественном отношении статистическая совокупность, отдельные единицы которой характеризуют количественные различия изучаемого признака или явления.
Количественная вариация может быть двух типов: прерывная (дискретная) и непрерывная.
Прерывный (дискретный) признак выражается только целым числом и не может иметь никаких промежуточных значений (например, число посещений, численность населения участка, число детей в семье, степень тяжести болезни в баллах и др.).
Непрерывный признак может принимать любые значения в определенных пределах, в том числе и дробные, и выражается лишь приближенно (например, вес – для взрослых можно ограничиться килограммами, а для новорожденных – граммами; рост, артериальное давление, время, потраченное на прием больного, и т. д.).
Цифровое значение каждого отдельного признака или явления, входящего в вариационный ряд, называется вариантой и обозначается буквой V . В математической литературе встречаются и другие обозначения, например x или y.
Вариационный ряд, где каждая варианта указана один раз, называется простым. Такие ряды используются в большинстве статистических задач в случае компьютерной обработки данных.
При увеличении числа наблюдений, как правило, встречаются повторяющиеся значения вариант. В этом случае создается сгруппированный вариационный ряд , где указывается число повторений (частота, обозначается буквой «р »).
Ранжированный вариационный ряд состоит из вариант, расположенных в порядке возрастания или убывания. Как простой, так и сгруппированный ряды могут быть составлены с ранжированием.
Интервальный вариационный ряд составляют с целью упрощения последующих вычислений, выполняемых без использования компьютера, при очень большом числе единиц наблюдения (более 1000).
Непрерывный вариационный ряд включает значения вариант, которые могут выражаться любыми значениями.
Если в вариационном ряде значения признака (варианты) заданы в виде отдельных конкретных чисел, то такой ряд называют дискретным .
Общими характеристиками значений признака, отражаемого в вариационном ряду, являются средние величины. Среди них наиболее применяемые: средняя арифметическая величина М, мода Мо и медиана Me. Каждая из этих характеристик своеобразна. Они не могут подменить друг друга и лишь в совокупности достаточно полно и в сжатой форме представляют собой особенности вариационного ряда.
Модой (Мо) называют значение наиболее часто встречающейся варианты.
Медиана (Me) – это значение варианты, делящей ранжированный вариационный ряд пополам (с каждой стороны медианы находится половина вариант). В редких случаях, когда имеется симметричный вариационный ряд, мода и медиана равны между собой и совпадают со значением средней арифметической.
Наиболее типичной характеристикой значений вариант является средняя арифметическая величина(М ). В математической литературе она обозначается .
Средняя арифметическая величина (M, ) – это общая количественная характеристика определенного признака изучаемых явлений, составляющих качественно однородную статистическую совокупность. Различают среднюю арифметическую простую и взвешенную. Средняя арифметическая простая вычисляется для простого вариационного ряда путем суммирования всех вариант и делением этой суммы на общее количество вариант, входящих в данный вариационный ряд. Вычисления проводятся по формуле:
 ,
,
где: М - средняя арифметическая простая;
ΣV - сумма вариант;
n - число наблюдений.
В сгруппированном вариационном ряду определяют взвешенную среднюю арифметическую. Формула ее вычисления:
 ,
,
где: М - средняя арифметическая взвешенная;
ΣVp - сумма произведений вариант на их частоты;
n - число наблюдений.
При большом числе наблюдений в случае ручных вычислений может применяться способ моментов.
Средняя арифметическая имеет следующие свойства:
· сумма отклонений вариант от средней (Σd ) равна нулю (см. табл. 15);
· при умножении (делении) всех вариант на один и тот же множитель (делитель) средняя арифметическая умножается (делится) на тот же множитель (делитель);
· если прибавить (вычесть) ко всем вариантам одно и то же число, средняя арифметическая увеличивается (уменьшается) на это же число.
Средние арифметические величины, взятые сами по себе, без учета вариабельности рядов, из которых они вычислены, могут не в полной мере отражать свойства вариационного ряда, в особенности когда необходимо сопоставление с другими средними. Близкие по значению средние могут быть получены из рядов с различной степенью рассеяния. Чем ближе друг к другу отдельные варианты по своей количественной характеристике, тем меньше рассеяние (колеблемость, вариабельность) ряда, тем типичнее его средняя.
Основными параметрами, которые позволяют оценить вариабельность признака, являются:
· Размах;
· Амплитуда;
· Среднее квадратическое отклонение;
· Коэффициент вариации.
Приблизительно о колеблемости признака можно судить по размаху и амплитуде вариационного ряда. Размах указывает на максимальную (V max) и минимальную (V min) варианты в ряду. Амплитуда (A m) является разностью этих вариант: A m = V max - V min .
Основной, общепринятой мерой колеблемости вариационного ряда являются дисперсия (D ). Но наиболее часто применяется более удобный параметр, вычисляемый на основе дисперсии - среднее квадратическое отклонение (σ ). Оно учитывает величину отклонения (d ) каждой варианты вариационного ряда от его средней арифметической (d=V - M ).
Поскольку отклонения вариант от средней могут быть положительными и отрицательными, то при суммировании они дают значение «0» (Sd=0 ). Чтобы избежать этого, величины отклонения (d ) возводятся во вторую степень и усредняются. Таким образом, дисперсия вариационного ряда является средним квадратом отклонений вариант от средней арифметической и вычисляется по формуле:
 .
.
Она является важнейшей характеристикой вариабельности и применяется для вычисления многих статистических критериев.
Поскольку дисперсия выражается квадратом отклонений, ее величина не может использоваться в сопоставлении со средней арифметической. Для этих целей применяется среднее квадратическое отклонение , которое обозначается знаком «Сигма» (σ ). Оно характеризует среднее отклонение всех вариант вариационного ряда от средней арифметической величины в тех же единицах, что и сама средняя величина, поэтому они могут использоваться совместно.
Среднее квадратическое отклонение определяют по формуле:

Указанная формула применяется при числе наблюдений (n ) больше 30. При меньшем числе n значение среднего квадратического отклонения будет иметь погрешность, связанную с математическим смещением (n - 1). В связи с этим, более точный результат может быть получен с помощью учета такого смещения в формуле расчета стандартного отклонения:
стандартное отклонение (s ) – это оценка среднеквадратического отклонения случайной величины Х относительно её математического ожидания на основе несмещённой оценки её дисперсии.
При значениях n > 30 среднее квадратическое отклонение (σ ) и стандартное отклонение (s ) будут одинаковыми (σ =s ). Поэтому в большинстве практических пособий эти критерии рассматриваются как разнозначные. В программе Excel вычисление стандартного отклонения может быть выполнено функцией =СТАНДОТКЛОН(диапазон). А с целью расчета среднего квадратического отклонения требуется создать соответствующую формулу.
Среднее квадратическое или стандартное отклонение позволяет определить, насколько значения признака могут отличаться от среднего значения. Предположим, существуют два города с одинаковой средней дневной температурой в летний период. Один их этих городов расположен на побережье, а другой на континенте. Известно, что в городах, расположенных на побережье, различия дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднее квадратическое отклонение дневных температур у прибрежного города будет меньше, чем у второго города. На практике это означает, что средняя температура воздуха каждого конкретного дня в городе, расположенного на континенте будет сильнее отличаться от среднего значения, чем в городе на побережье. Кроме того стандартное отклонение позволяет оценить возможные отклонения температуры от средней с требуемым уровнем вероятности.
Согласно теории вероятности, в явлениях, подчиняющихся нормальному закону распределения, между значениями средней арифметической, среднего квадратического отклонения и вариантами существует строгая зависимость (правило трех сигм ). Например, 68,3% значений варьирующего признака находятся в пределах М ± 1σ , 95,5% - в пределах М ± 2σ и 99,7% - в пределах М ± 3σ .
Величина среднего квадратического отклонения позволяет судить о характере однородности вариационного ряда и исследуемой группы. Если величина среднего квадратического отклонения небольшая, то это свидетельствует о достаточно высокой однородности изучаемого явления. Среднюю арифметическую в таком случае следует признать вполне характерной для данного вариационного ряда. Однако слишком малая величина сигмы заставляет думать об искусственном подборе наблюдений. При очень большой сигме средняя арифметическая в меньшей степени характеризует вариационный ряд, что говорит о значительной вариабельности изучаемого признака или явления или о неоднородности исследуемой группы. Однако сопоставление величины среднего квадратического отклонения возможно только для признаков одинаковой размерности. Действительно, если сравнивать разнообразие веса новорожденных детей и взрослых, мы всегда получим более высокие значения сигмы у взрослых.
Сравнение вариабельности признаков различной размерности может быть выполнено с помощью коэффициента вариации . Он выражает разнообразие в процентах от средней величины, что позволяет производить сравнение различных признаков. Коэффициент вариации в медицинской литературе обозначается знаком «С », а в математической «v » и вычисляемого по формуле:
 .
.
Значения коэффициента вариации менее 10% свидетельствует о малом рассеянии, от 10 до 20% – о среднем, более 20% – о сильном рассеянии вариант вокруг средней арифметической.
Средняя арифметическая величина, как правило, вычисляется на основе данных выборочной совокупности. При повторных исследованиях под влиянием случайных явлений средняя арифметическая может изменяться. Это обусловлено тем, что исследуется, как правило, только часть возможных единиц наблюдения, то есть выборочная совокупность. Информация обо всех возможных единицах, представляющих изучаемое явление, может быть получена при изучении всей генеральной совокупности, что не всегда возможно. В то же время с целью обобщения данных эксперимента представляет интерес величина средней в генеральной совокупности. Поэтому для формулировки общего вывода об изучаемом явлении, результаты, полученные на основе выборочной совокупности, должны быть, перенесены на генеральную совокупность статистическими методами.
Чтобы определить степень совпадения выборочного исследования и генеральной совокупности, необходимо оценить величину ошибки, которая неизбежно возникает при выборочном наблюдении. Такая ошибка называется «Ошибкой репрезентативности » или «Средней ошибкой средней арифметической». Она фактически является разностью между средними, полученными при выборочном статистическом наблюдении, и аналогичными величинами, которые были бы получены при сплошном исследовании того же объекта, т.е. при изучении генеральной совокупности. Поскольку выборочная средняя является случайной величиной, такой прогноз выполняется с приемлемым для исследователя уровнем вероятности. В медицинских исследованиях он составляет не менее 95%.
Ошибку репрезентативности нельзя смешивать с ошибками регистрации или ошибками внимания (описки, просчеты, опечатки и др.), которые должны быть сведены до минимума адекватной методикой и инструментами, применяемыми при проведении эксперимента.
Величина ошибки репрезентативности зависит как от объема выборки, так и от вариабельности признака. Чем больше число наблюдений, тем ближе выборка к генеральной совокупности и тем меньше ошибка. Чем более изменчив признак, тем больше величина статистической ошибки.
На практике для определения ошибки репрезентативности в вариационных рядах пользуются следующей формулой:
 ,
,
где: m – ошибка репрезентативности;
σ – среднее квадратическое отклонение;
n – число наблюдений в выборке.
Из формулы видно, что размер средней ошибки прямо пропорционален среднему квадратическому отклонению, т. е. вариабельности изучаемого признака, и обратно пропорционален корню квадратному из числа наблюдений.
При выполнении статистического анализа на основе вычисления относительных величин построение вариационного ряда не является обязательным. При этом определение средней ошибки для относительных показателей может выполняться по упрощенной формуле:
 ,
,
где: Р – величина относительного показателя, выраженного в процентах, промилле и т.д.;
q – величина, обратная Р и выраженная как (1-Р), (100-Р), (1000-Р) и т. д., в зависимости от основания, на которое рассчитан показатель;
n – число наблюдений в выборочной совокупности.
Однако, указанная формула вычисления ошибки репрезентативности для относительных величин может применяться только в том случае, когда значение показателя меньше его основания. В ряде случаев расчета интенсивных показателей такое условие не соблюдается, и показатель может выражаться числом более 100% или 1000%о. В такой ситуации выполняется построение вариационного ряда и вычисление ошибки репрезентативности по формуле для средних величин на основе среднего квадратического отклонения.
Прогнозирование величины средней арифметической в генеральной совокупности выполняется с указанием двух значений – минимального и максимального. Эти крайние значения возможных отклонений, в пределах которых может колебаться искомая средняя величина генеральной совокупности, называются «Доверительные границы ».
Постулатами теории вероятностей доказано, что при нормальном распределении признака с вероятностью 99,7%, крайние значения отклонений средней будут не больше величины утроенной ошибки репрезентативности (М ± 3m ); в 95,5% – не больше величины удвоенной средней ошибки средней величины (М ± 2m ); в 68,3% – не больше величины одной средней ошибки (М ± 1m ) (рис. 9).

| P% |
Рис. 9. Плотность вероятностей нормального распределения.
Отметим, что приведенное выше утверждение справедливо только для признака, который подчиняется нормальному закону распределения Гаусса.
Большинство экспериментальных исследований, в том числе и в области медицины, связано с измерениями, результаты которых могут принимать практически любые значения в заданном интервале, поэтому, как правило, описываются моделью непрерывных случайных величин. В связи с этим в большинстве статистических методов рассматриваются непрерывные распределения. Одним из таких распределений, имеющим основополагающую роль в математической статистике, является нормальное, или гауссово, распределение .
Это объясняется целым рядом причин.
1. Прежде всего, многие экспериментальные наблюдения можно успешно описать с помощью нормального распределения. Следует сразу же отметить, что не существует распределений эмпирических данных, которые были бы в точности нормальными, поскольку нормально распределенная случайная величина находится в пределах от до , чего никогда не встречается на практике. Однако нормальное распределение очень часто хорошо подходит как приближение.
Проводятся ли измерения веса, роста и других физиологических параметров организма человека - везде на результаты оказывает влияние очень большое число случайных факторов (естественные причины и ошибки измерения). Причем, как правило, действие каждого из этих факторов незначительно. Опыт показывает, что результаты именно в таких случаях будут распределены приближенно нормально.
2. Многие распределения, связанные со случайной выборкой, при увеличении объема последней переходят в нормальное.
3. Нормальное распределение хорошо подходит в качестве приближенного описания других непрерывных распределений (например, асимметричных).
4. Нормальное распределение обладает рядом благоприятных математических свойств, во многом обеспечивших его широкое применение в статистике.
В то же время следует отметить, что в медицинских данных встречается много экспериментальных распределений, описание которых моделью нормального распределения невозможно. Для этого в статистке разработаны методы, которые принято называть «Непараметрическими».
Выбор статистического метода, который подходит для обработки данных конкретного эксперимента, должен производиться в зависимости от принадлежности полученных данных к нормальному закону распределения. Проверка гипотезы на подчинение признака нормальному закону распределения выполняется с помощью гистограммы распределения частот (графика), а также ряда статистических критериев. Среди них:
Критерий асимметрии (b );
Критерий проверки на эксцесс (g );
Критерий Шапиро – Уилкса (W ) .
Анализ характера распределения данных (его еще называют проверкой на нормальность распределения) осуществляется по каждому параметру. Чтобы уверенно судить о соответствии распределения параметра нормальному закону, необходимо достаточно большое число единиц наблюдения (не менее 30 значений).
Для нормального распределения критерии асимметрии и эксцесса принимают значение 0. Если распределение смещено вправо b > 0 (положительная асимметрия), при b < 0 - график распределения смещен влево (отрицательная асимметрия). Критерий асимметрии проверяет форму кривой распределения. В случае нормального закона g =0. При g > 0 кривая распределения острее, если g < 0 пик более сглаженный, чем функция нормального распределения.
Для проверки на нормальность по критерию Шапиро – Уилкса требуется найти значение этого критерия по статистическим таблицам при необходимом уровне значимости и в зависимости от числа единиц наблюдения (степеней свободы). Приложение 1. Гипотеза о нормальности отвергается при малых значениях этого критерия, как правило, при w <0,8.
Пример решения контрольной работы по математической статистике
Задача 1
Исходные данные : студенты некоторой группы, состоящей из 30 человек сдали экзамен по курсу «Информатика». Полученные студентами оценки образуют следующий ряд чисел:
I. Составим вариационный ряд
|
m x |
w x |
m x нак |
w x нак |
|
|
Итого: |
II. Графическое представление статистических сведений.

III. Числовые характеристики выборки.
1. Среднее арифметическое
2. Среднее геометрическое
3.
Мода

4. Медиана
222222333333333 | 3 34444444445555

5. Выборочная дисперсия

7. Коэффициент вариации

8. Ассиметрия
9. Коэффициент ассиметрии

10. Эксцесс
11. Коэффициент эксцесса

Задача 2
Исходные данные : студенты некоторой группы написали выпускную контрольную работу. Группа состоит из 30 человек. Набранные студентами баллы образуют следующий ряд чисел
Решение
I. Так как признак принимает много различных значений, то для него построим интервальный вариационный ряд. Для этого сначала зададим величину интервала h . Воспользуемся формулой Стэрджера
Составим шкалу интервалов. При этом за верхнюю границу первого интервала примем величину, определяемую по формуле:
Верхние границы последующих интервалов определим по следующей рекуррентной формуле:
 ,
тогда
,
тогда
Построение
шкалы интервалов заканчиваем, так как
верхняя граница очередного интервала
стала больше или равна максимальному
значению выборки
 .
.
|
|
|
|
|
|




II. Графическое отображение интервального вариационного ряда


III. Числовые характеристики выборки
Для определения числовых характеристик выборки составим вспомогательную таблицу
|
|
|
|
|
|
|
|
Сумма : |





1. Среднее арифметическое

2. Среднее геометрическое
3.
Мода

4. Медиана
10 11 12 12 13 13 13 13 14 14 14 14 15 15 15 |15 15 15 16 16 16 16 16 17 17 18 19 19 20 20

5. Выборочная дисперсия

6. Выборочное стандартное отклонение

7. Коэффициент вариации

8. Ассиметрия

9. Коэффициент ассиметрии

10. Эксцесс

11. Коэффициент эксцесса

Задача 3
Условие : цена деления шкалы амперметра равна 0,1 А. Показания округляют до ближайшего целого деления. Найти вероятность того, что при отсчете будет сделана ошибка, превышающая 0,02 А.
Решение.
Ошибку округления отсчета можно рассматривать как случайную величину Х , которая распределена равномерно в интервале между двумя соседними целыми делениями. Плотность равномерного распределения
 ,
,
где
 - длина интервала, в котором заключены
возможные значения Х
;
вне этого интервала
- длина интервала, в котором заключены
возможные значения Х
;
вне этого интервала
 В данной задаче длина интервала, в
котором заключены возможные значения
Х
, равна 0,1,
поэтому
В данной задаче длина интервала, в
котором заключены возможные значения
Х
, равна 0,1,
поэтому

Ошибка отсчета превысит 0,02 если она будет заключена в интервале (0,02; 0,08). Тогда
Ответ: р =0,6
Задача 4
Исходные данные: математическое ожидание и стандартное отклонение нормально распределенного признака Х соответственно равны 10 и 2. Найти вероятность того, чтов результате испытания Х примет значение, заключенное в интервале (12, 14).
Решение.
Воспользуемся формулой

И теоретическими частотами



Для Х ее математическое ожидание M(X) и дисперсию D(X). Решение . Найдем функцию распределения F(x) случайной величины... ошибка выборки). Составим вариационный ряд Ширина интервала составит : Для каждого значения ряда подсчитаем, какое количество...
Решение: уравнение с разделяющимися переменными
РешениеВ виде Для нахождения частного решения неоднородного уравнения составим систему Решим полученную систему... ; +47; +61; +10; -8. Построить интервальный вариационный ряд . Дать статистические оценки среднего значения...
Решение: Проведем расчет цепных и базисных абсолютных приростов, темпов роста, темпов прироста. Полученные значения сведем в таблицу 1
РешениеОбъем производства продукции. Решение : Средняя арифметическая интервального вариационного ряда вычисляется следующим образом: за... Предельная ошибка выборки с вероятностью 0,954 (t=2) составит : Δ w = t*μ = 2*0,0146 = 0,02927 Определим границы...
Решение. Признак
РешениеО трудовом стаже которых и составили выборку. Средний по выборке стаж... рабочего дня этих сотрудников и составили выборку. Средняя по выборке продолжительность... 1,16, уровень значимости α = 0,05. Решение . Вариационный ряд данной выборки имеет вид: 0,71 ...
Рабочая учебная программа по биологии для 10-11 классов Составитель: Поликарпова С. В
Рабочая учебная программаПростейших схем скрещивания» 5 Л.р. «Решение элементарных генетических задач» 6 Л.р. «Решение элементарных генетических задач» 7 Л.р. « ... , 110, 115, 112, 110. Составьте вариационный ряд , начертите вариационную кривую, найдите среднюю величину признака...