Уравнение тренда представляет собой. Методы сглаживания колебаний
Покажем пример подробного расчета параметров уравнения тренда на основе следующих данных (см. таблицу) с использованием калькулятора .
Линейное уравнение тренда имеет вид y = at + b.
1. Находим параметры уравнения методом наименьших квадратов
.
Система уравнений МНК:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y | y(t) | (y-y cp) 2 | (y-y(t)) 2 | (t-t p) 2 | (y-y(t)) : y |
| 1 | 17.4 | 1 | 302.76 | 17.4 | 12.26 | 895.01 | 26.47 | 30.25 | 0.3 |
| 2 | 26.9 | 4 | 723.61 | 53.8 | 18.63 | 416.84 | 68.39 | 20.25 | 0.31 |
| 3 | 23 | 9 | 529 | 69 | 25 | 591.3 | 4.02 | 12.25 | 0.0872 |
| 4 | 23.7 | 16 | 561.69 | 94.8 | 31.38 | 557.75 | 58.98 | 6.25 | 0.32 |
| 5 | 27.2 | 25 | 739.84 | 136 | 37.75 | 404.68 | 111.4 | 2.25 | 0.39 |
| 6 | 34.5 | 36 | 1190.25 | 207 | 44.13 | 164.27 | 92.72 | 0.25 | 0.28 |
| 7 | 50.7 | 49 | 2570.49 | 354.9 | 50.5 | 11.45 | 0.0383 | 0.25 | 0.0039 |
| 8 | 61.4 | 64 | 3769.96 | 491.2 | 56.88 | 198.34 | 20.44 | 2.25 | 0.0736 |
| 9 | 69.3 | 81 | 4802.49 | 623.7 | 63.25 | 483.27 | 36.56 | 6.25 | 0.0872 |
| 10 | 94.4 | 100 | 8911.36 | 944 | 69.63 | 2216.84 | 613.62 | 12.25 | 0.26 |
| 11 | 61.1 | 121 | 3733.21 | 672.1 | 76 | 189.98 | 222.11 | 20.25 | 0.24 |
| 12 | 78.2 | 144 | 6115.24 | 938.4 | 82.38 | 953.78 | 17.46 | 30.25 | 0.0534 |
| 78 | 567.8 | 650 | 33949.9 | 4602.3 | 567.8 | 7083.5 | 1272.21 | 143 | 2.41 |
Для наших данных система уравнений имеет вид:
12a 0 + 78a 1 = 567.8
78a 0 + 650a 1 = 4602.3
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = 6.37, a 1 = 5.88
Примечание: значения столбца №6 y(t) рассчитываются на основе полученного уравнения тренда. Например, t = 1: y(1) = 6.37*1 + 5.88 = 12.26
Уравнение тренда
y = 6.37 t + 5.88Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
![]()
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве тренда.
Средние значения:
![]()
![]()
![]()
Дисперсия
![]()
Среднеквадратическое отклонение
Коэффициент эластичности
![]()
Коэффициент эластичности меньше 1. Следовательно, при изменении Х на 1%, Y изменится менее чем на 1%. Другими словами - влияние Х на Y не существенно.
Коэффициент детерминации

т.е. в 82.04 % случаев влияет на изменение данных. Другими словами - точность подбора уравнения тренда - высокая
2. Анализ точности определения оценок параметров уравнения тренда
.
Дисперсия ошибки уравнения.
где m = 1 - количество влияющих факторов в модели тренда.
Стандартная ошибка уравнения.
3. Проверка гипотез относительно коэффициентов линейного уравнения тренда
.
1) t-статистика. Критерий Стьюдента.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (10;0.025) = 2.228
>
Статистическая значимость коэффициента a 0 подтверждается. Оценка параметра a 0 является значимой и тренд у временного ряда существует..
Статистическая значимость коэффициента a 1 не подтверждается.
Доверительный интервал для коэффициентов уравнения тренда
.
Определим доверительные интервалы коэффициентов тренда, которые с надежность 95% будут следующими:
(a 1 - t набл S a 1 ;a 1 + t набл S a 1)
(6.375 - 2.228*0.943; 6.375 + 2.228*0.943)
(4.27;8.48)
(a 0 - t набл S a 0 ;a 0 + t набл S a 0)
(5.88 - 2.228*6.942; 5.88 + 2.228*6.942)
(-9.59;21.35)
Так как точка 0 (ноль) лежит внутри доверительного интервала, то интервальная оценка коэффициента a 0 статистически незначима.
2) F-статистика. Критерий Фишера.
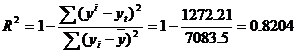
Fkp = 4.84
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Проверка на наличие автокорреляции остатков
.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция)
определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция
, нежели отрицательная автокорреляция
. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция
фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию
, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности
: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения e i с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения e i (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости e i от e i-1
Критерий Дарбина-Уотсона
.
Этот критерий является наиболее известным для обнаружения автокорреляции.
При статистическом анализе уравнения регрессии на начальном этапе часто проверяют выполнимость одной предпосылки: условия статистической независимости отклонений между собой. При этом проверяется некоррелированность соседних величин e i .
| y | y(x) | e i = y-y(x) | e 2 | (e i - e i-1) 2 |
| 17.4 | 12.26 | 5.14 | 26.47 | 0 |
| 26.9 | 18.63 | 8.27 | 68.39 | 9.77 |
| 23 | 25 | -2 | 4.02 | 105.57 |
| 23.7 | 31.38 | -7.68 | 58.98 | 32.2 |
| 27.2 | 37.75 | -10.55 | 111.4 | 8.26 |
| 34.5 | 44.13 | -9.63 | 92.72 | 0.86 |
| 50.7 | 50.5 | 0.2 | 0.0384 | 96.53 |
| 61.4 | 56.88 | 4.52 | 20.44 | 18.71 |
| 69.3 | 63.25 | 6.05 | 36.56 | 2.33 |
| 94.4 | 69.63 | 24.77 | 613.62 | 350.63 |
| 61.1 | 76 | -14.9 | 222.11 | 1574.09 |
| 78.2 | 82.38 | -4.18 | 17.46 | 115.03 |
| 1272.21 | 2313.98 |
Для анализа коррелированности отклонений используют статистику Дарбина-Уотсона
:

![]()
Критические значения d 1 и d 2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n = 12 и количества объясняющих переменных m=1.
Автокорреляция отсутствует, если выполняется следующее условие:
d 1 < DW и d 2 < DW < 4 - d 2 .
Не обращаясь к таблицам, можно пользоваться приблизительным правилом и считать, что автокорреляция остатков отсутствует, если 1.5 < DW < 2.5. Поскольку 1.5 < 1.82 < 2.5, то автокорреляция остатков отсутствует
.
Для более надежного вывода целесообразно обращаться к табличным значениям.
По таблице Дарбина-Уотсона для n=12 и k=1 (уровень значимости 5%) находим: d 1 = 1.08; d 2 = 1.36.
Поскольку 1.08 < 1.82 и 1.36 < 1.82 < 4 - 1.36, то автокорреляция остатков отсутствует
.
Проверка наличия гетероскедастичности
.
1) Методом графического анализа остатков
.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения e i , либо их квадраты e 2 i .
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена
.
Коэффициент ранговой корреляции Спирмена
.
Присвоим ранги признаку Y и фактору X. Найдем сумму разности квадратов d 2 .
По формуле вычислим коэффициент ранговой корреляции Спирмена.
![]()
| t | e i | ранг X, d x | ранг e i , d y | (d x - d y) 2 |
| 1 | -5.14 | 1 | 4 | 9 |
| 2 | -8.27 | 2 | 2 | 0 |
| 3 | 2 | 3 | 7 | 16 |
| 4 | 7.68 | 4 | 9 | 25 |
| 5 | 10.55 | 5 | 11 | 36 |
| 6 | 9.63 | 6 | 10 | 16 |
| 7 | -0.2 | 7 | 6 | 1 |
| 8 | -4.52 | 8 | 5 | 9 | t табл (n-m-1;α/2) = (10;0.05/2) = 2.228
23.Расчет параметров линейного тренда.
Основной тенденцией развития (трендом) называется плавное и устойчивое изменение уровня явления во времени, свободное от случайных колебаний.
Задача состоит в том, чтобы выявить общую тенденцию в изменении уровней ряда, освобожденную от действия различных случайных факторов. С этой целью ряды динамики подвергаются обработке методами укрупнения интервалов, скользящей средней и аналитического выравнивания.
*Одним из наиболее простых методов изучения основной тенденции в рядах динамики является укрупнение интервалов. Он основан на укрупнении периодов времени, к которым относятся уровни ряда динамики (одновременно уменьшается количество интервалов). Например, ряд ежесуточного выпуска продукции заменяется рядом месячного выпуска продукции и т.д. Средняя, исчисленная по укрупненным^ интервалам, позволяет выявлять направление и характер (ускорение или замедление роста) основной тенденции развития.
* Выявление основной тенденции может осуществляться также методом скользящи (подвижной) средней. Сущность его заключается в том, что исчисляется средний уровень из определенного числа, обычно нечетного (3, 5, 7 и т.д.), первыхтю счету уровней ряда, затем - из такого же числа уровней, но начиная со второго по счету, далее - начиная с третьего и т.д. Таким образом, средняя как бы «скользит» по ряду динамики, передвигаясь на один срок.
на два члена в начале и конце ряда. Он меньше, чем фактический подвержен колебаниям из-за случайных причин, и четче, в виде некоторой плавной линии на графике, выражает основную тенденцию роста урожайности за изучаемый период, связанную с действием долговременно существующих причин и условий развития.
Недостатком сглаживания ряда является «укорачивание» сглаженного ряда по сравнению с фактическим, а следовательно, потеря информации.
Рассмотренные приемы сглаживания динамических рядов (укрупнение интервалов и метод скользящей средней) дают возможность определить лишь общую тенденцию развития явления, более или менее освобожденную от случайных и волнообразных колебаний. Однако получить обобщенную статистическую модель тренда посредством этих методов нельзя.
*Для того чтобы дать количественную модель, выражающую основную тенденцию изменения уровней динамического ряда во времени, используется аналитическое выравнивание ряда динамики.
где yt - уровни динамического ряда, вычисленные по соответствующему аналитическому уравнению на момент времени t.
Определение теоретических (расчетных) уровней yt производится на основе так называемой адекватной математической модели, которая наилучшим образом отображает (аппроксимирует) основную тенденцию ряда динамики. Выбор типа модели зависит от цели исследования и должен быть основан на теоретическом анализе, выявляющем характер развития явления, а также на графическом изображении ряда динамики (линейной диаграмме).
Например, простейшими моделями (формулами), выражающими тенденцию развития, являются:
линейная функция - прямая yt = a0 + a1t,
где a0,a1 - параметры уравнения; t - время;
показательная функция yt = A0A1t
степенная функция - кривая второго порядка (парабола)
В тех случаях, когда требуется особо точное изучение тенденции развития (например, модели тренда для прогнозирования), при выборе вида адекватной функции можно использовать специальные критерии математической статистики.
Расчет параметров функции обычно производится методом наименьших квадратов, в котором в качестве решения принимается точка минимума суммы квадратов отклонений между теоретическими и эмпиричесими уровнями:

где yt - выравненные (расчетные) уровни; yt - фактические уровни.
Параметры уравнения а,-, удовлетворяющие этому условию, могут быть найдены решением системы нормальных уравнений. На основе найденного уравнения тренда вычисляются выравненные уровни. Таким образом, выравнивание ряда динамики заключается в замене фактических уровней у,- плавно изменяющимися уровнями У(, наилучшим образом аппроксимирующилми статистические данные.
Выравнивание по прямой используется, как правило, в тех случаях, когда абсолютные приросты практически постоянны, т. е. когда уровни изменяются в арифметической прогрессии (или близко к ней).
Выравнивание по показательной функции используется в тех случаях, когда ряд отражает развитие в геометрической прогрессии, т. е. когда цепные коэффициенты роста практически постоянны.
Рассмотрим «технику» выравнивания ряда динамики по прямой: yt=a0+a1t
Параметры а0, а1 согласно методу наименьших квадратов находятся решением следующей системы нормальных уравнений, полученной путем алгебраического преобразования условия
где у - фактические (эмпирические) уровни ряда; t - время (порядковый номеа периода или момента времени).

В главе 2 было рассмотрено понятие о тенденции временного ряда, т.е. тенденции динамики развития изучаемого показателя. Задача данной главы состоит в том, чтобы рассмотреть основные типы таких тенденций, их свойства, отражаемые с большей или меньшей степенью полноты уравнением линии тренда. Укажем при этом, что в отличие от простых систем механики тенденции изменения показателей сложных социальных, экономических, биологических и технических систем только с некоторым приближением отражаются тем или иным уравнением, линией тренда.
В данной главе рассматриваются далеко не все известные в математике линии и их уравнения, а лишь набор их сравнительно простых форм, который мы считаем достаточным для отображения и анализа большинства встречающихся на практике тенденций временных рядов. При этом желательно всегда выбирать из нескольких типов линий, достаточно близко выражающих тенденцию, более простую линию. Этот «принцип простоты» обоснован тем, что чем сложнее уравнение линии тренда, чем большее число параметров оно содержит, тем при равной степени приближения труднее дать надежную оценку этих параметров по ограниченному числу уровней ряда и тем больше ошибка оценки этих параметров, ошибки прогнозируемых уровней.
4.1. Прямолинейный тренд и его свойства
Самым простым типом линии тренда является прямая линия, описываемая линейным (т.е. первой степени) уравнением тренда:
где
 -
выровненные, т.е. лишенные колебаний,
уровни тренда для лет с номеромi;
-
выровненные, т.е. лишенные колебаний,
уровни тренда для лет с номеромi;
а - свободный член уравнения, численно равный среднему выровненному уровню для момента или периода времени, принятого за начало отсчета, т.е. для
t = 0;
b - средняя величина изменения уровней ряда за единицу изменения времени;
ti - номера моментов или периодов времени, к которым относятся уровни временного ряда (год, квартал, месяц, дата).
Среднее изменение уровней ряда за единицу времени - главный параметр и константа прямолинейного тренда. Следовательно, этот тип тренда подходит для отображения тенденции примерно равномерных изменений уровней: равных в среднем абсолютных приростов или абсолютных сокращений уровней за равные промежутки времени. Практика показывает, что такой характер динамики встречается достаточно часто. Причина близких к равномерному абсолютных изменений уровней ряда состоит в следующем: многие явления, как, например, урожайность сельскохозяйственных культур, численность населения региона, города, сумма дохода населения, среднее потребление какого-либо продовольственного товара и др., зависят от большого числа различных факторов. Одни из них влияют в сторону ускоренного роста изучаемого явления, другие - в сторону замедленного роста, третьи - в направлении сокращения уровней и т.д. Влияние разнонаправленных и разноускоренных (замедленных) сил факторов взаимно усредняется, частично взаимно погашается, а равнодействующая их влияний приобретает характер, близкий к равномерной тенденции. Итак, равномерная тенденция динамики (или застоя) - это результат сложения влияния большого количества факторов на изменение изучаемого показателя.
Графическое изображение прямолинейного тренда - прямая линия в системе прямоугольных координат с линейным (арифметическим) масштабом на обеих осях. Пример линейного тренда дан на рис. 4.1.
Абсолютные изменения уровней в разные годы не были точно одинаковыми, но общая тенденция сокращения численности занятых в народном хозяйстве очень хорошо отражается прямолинейным трендом. Его параметры вычислены в гл. 5 (табл. 5.3).

Основные свойства тренда в форме прямой линии таковы:
Равные изменения за равные промежутки времени;
Если средний абсолютный прирост - положительная величина, то относительные приросты или темпы прироста постепенно уменьшаются;
Если среднее абсолютное изменение - отрицательная величина, то относительные изменения или темпы сокращения постепенно увеличиваются по абсолютной величине снижения к предыдущему уровню;
Если тенденция к сокращению уровней, а изучаемая величина является по определению положительной, то среднее изменение b не может быть больше среднего уровняа;
При линейном тренде ускорение, т.е. разность абсолютных изменений за последовательные периоды, равно нулю.
Свойства линейного тренда иллюстрирует
табл. 4.1. Уравнение тренда:
 =
100 +20 *ti.
=
100 +20 *ti.
Показатели динамики при наличии тенденции сокращения уровней приведены в табл. 4.2.
Таблица 4.1
Показатели динамики при линейном тренде
к увеличению уровней
 =
100 +20 *ti.
=
100 +20 *ti.
|
Номер периода ti |
|
Темпы (цепные), % |
Ускорение |
|

Таблица 4.2
Показатели динамики при линейном тренде
сокращения уровней:
 =
200 -20 *ti.
=
200 -20 *ti.
|
Номер периода ti |
|
Абсолютное изменение к предыдущему периоду |
Темп к предыдущему периоду, % |
Ускорение |

a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
и таблица следующего вида:
| t | y | t 2 | y 2 | t y | y(t) |
| 1 | |||||
| ... | ... | ... | ... | ... | ... |
| N | |||||
| ИТОГО | ∑ | ∑ | ∑ | ∑ | ∑ |
Инструкция . Укажите количество данных (количество строк). Полученное решение сохраняется в файле Word и Excel .
Тенденция временного ряда характеризует совокупность факторов, оказывающих долговременное влияние и формирующих общую динамику изучаемого показателя.
Способ отсчета времени от условного начала
Для определения параметров математической функции при анализе тренда в рядах динамики используется способ отсчета времени от условного начала. Он основан на обозначении в ряду динамики показаний времени таким образом, чтобы ∑t i . При этом в ряду динамики с нечетным числом уровней порядковый номер уровня, находящегося в середине ряда, обозначают через нулевое значение и принимают его за условное начало отсчета времени с интервалом +1 всех последующих уровней и –1 всех предыдущих уровней. Например, при обозначения времени будут: –2, –1, 0, +1, +2 . При четном числе уровней порядковые номера верхней половины ряда (от середины) обозначаются числами: –1, –3, –5 , а нижней половины ряда обозначаются +1, +3, +5 .Пример . Статистическое изучение динамики численности населения.
- С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
- С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
- Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
| 1990 | 1996 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
| 1249 | 1133 | 1043 | 1030 | 1016 | 1005 | 996 | 985 | 975 | 968 |
а) Линейное уравнение тренда имеет вид y = bt + a
1. Находим параметры уравнения методом наименьших квадратов
. Используем способ отсчета времени от условного начала.
Система уравнений МНК для линейного тренда имеет вид:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y |
| -9 | 1249 | 81 | 1560001 | -11241 |
| -7 | 1133 | 49 | 1283689 | -7931 |
| -5 | 1043 | 25 | 1087849 | -5215 |
| -3 | 1030 | 9 | 1060900 | -3090 |
| -1 | 1016 | 1 | 1032256 | -1016 |
| 1 | 1005 | 1 | 1010025 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 |
| 5 | 985 | 25 | 970225 | 4925 |
| 7 | 975 | 49 | 950625 | 6825 |
| 9 | 968 | 81 | 937024 | 8712 |
| 0 | 10400 | 330 | 10884610 | -4038 |
Для наших данных система уравнений примет вид:
10a 0 + 0a 1 = 10400
0a 0 + 330a 1 = -4038
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = -12.236, a 1 = 1040
Уравнение тренда:
y = -12.236 t + 1040
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе уравнения тренда к исходным данным.
![]()
б) выравнивание по параболе
Уравнение тренда имеет вид y = at 2 + bt + c
1. Находим параметры уравнения методом наименьших квадратов.
Система уравнений МНК:
a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y
a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt
a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
| t | y | t 2 | y 2 | t y | t 3 | t 4 | t 2 y |
| -9 | 1249 | 81 | 1560001 | -11241 | -729 | 6561 | 101169 |
| -7 | 1133 | 49 | 1283689 | -7931 | -343 | 2401 | 55517 |
| -5 | 1043 | 25 | 1087849 | -5215 | -125 | 625 | 26075 |
| -3 | 1030 | 9 | 1060900 | -3090 | -27 | 81 | 9270 |
| -1 | 1016 | 1 | 1032256 | -1016 | -1 | 1 | 1016 |
| 1 | 1005 | 1 | 1010025 | 1005 | 1 | 1 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 | 27 | 81 | 8964 |
| 5 | 985 | 25 | 970225 | 4925 | 125 | 625 | 24625 |
| 7 | 975 | 49 | 950625 | 6825 | 343 | 2401 | 47775 |
| 9 | 968 | 81 | 937024 | 8712 | 729 | 6561 | 78408 |
| 0 | 10400 | 330 | 10884610 | -4038 | 0 | 19338 | 353824 |
Для наших данных система уравнений имеет вид
10a 0 + 0a 1 + 330a 2 = 10400
0a 0 + 330a 1 + 0a 2 = -4038
330a 0 + 0a 1 + 19338a 2 = 353824
Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5
Уравнение тренда:
y = 1.258t 2 -12.236t+998.5
Ошибка аппроксимации для параболического уравнения тренда.
![]()
Поскольку ошибка меньше 7%, то данное уравнение можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный прогноз.
Определим среднеквадратическую ошибку прогнозируемого показателя.

m = 1 - количество влияющих факторов в уравнении тренда.
Uy = y n+L ± K
где

L - период упреждения; у n+L - точечный прогноз по модели на (n + L)-й момент времени; n - количество наблюдений во временном ряду; Sy - стандартная ошибка прогнозируемого показателя; T табл - табличное значение критерия Стьюдента для уровня значимости α и для числа степеней свободы, равного n-2
.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (8;0.025) = 2.306
Точечный прогноз, t = 10: y(10) = 1.26*10 2 -12.24*10 + 998.5 = 1001.89 тыс. чел.
1001.89 - 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный прогноз:
t = 9+1 = 10: (930.76;1073.02)
Тренд - это закономерность описывающая подъем или падение показателя в динамике. Если изобразить любой динамический ряд (статистические данные, представляющие собой список зафиксированных значений изменяемого показателя во времени) на графике, часто выделяется определенный угол – кривая либо постепенно идет на увеличение или на уменьшение, в таких случаях принято говорить, что ряд динамики имеет тенденцию (к росту или падению соответственно).
Тренд как модель
Если же построить модель, описывающую это явление, то получается довольно простой и очень удобный инструмент для прогнозирования не требующий каких-либо сложных вычислений или временных затрат на проверку значимости или адекватности влияющих факторов.
Итак, что же собой представляет тренд как модель? Это совокупность расчетных коэффициентов уравнения, которые выражают регрессионную зависимость показателя (Y) от изменения времени (t). То есть, это точно такая же регрессия, как и те, что мы рассматривали ранее, только влияющим фактором здесь выступает именно показатель времени.
Важно!
В расчетах под t обычно подразумевается не год, номер месяца или недели, а именно порядковый номер периода в изучаемой статистической совокупности – динамическом ряде. К примеру, если динамический ряд изучается за несколько лет, а данные фиксировались ежемесячно, то использовать обнуляющуюся нумерацию месяцев, с 1 по 12 и опять сначала, в корне неверно. Также неверно в случае, если изучение ряда начинается, к примеру, с марта месяца в качестве значения t использовать 3 (третий месяц в году), если это первое значение в изучаемой совокупности, то его порядковый номер должен быть 1.
Модель линейного тренда
Как и любая другая регрессия, тренд может быть как линейным (степень влияющего фактора t равна 1) так и нелинейным (степень больше или меньше единицы). Так как линейная регрессия является самой простейшей, хотя далеко не всегда самой точной, то рассмотрим более детально именно этот тип тренда.
Общий вид уравнения линейного тренда:
Y(t) = a 0 + a 1 *t + Ɛ
Где a 0 – это нулевой коэффициент регрессии, то есть, то каким будет Y в случае, если влияющий фактор будет равен нулю, a 1 – коэффициент регрессии, который выражает степень зависимости исследуемого показателя Y от влияющего фактора t, Ɛ – случайная компонента или стандартная ошибка, по сути являет собой разницу между реально существующими значениями Y и расчетными. t – это единственный влияющий фактор – время.
Чем более выраженная тенденция роста показателя или его падения, тем будет больше коэффициент a 1 . Соответственно, предполагается, что константа a 0 совместно со случайной компонентой Ɛ отражают остальные регрессионные влияния, помимо времени, то есть всех прочих возможных влияющих факторов.
Рассчитать коэффициенты модели можно стандартным Методом наименьших квадратов (МНК). Со всеми этими расчетами Microsoft Excel справляется на ура самостоятельно, при чем, чтобы получить модель линейного тренда либо готовый прогноз существует целых пять способов, которые мы по отдельности разберем ниже.
Графический способ получения линейного тренда
В этом и во всех дальнейших примерах будем использовать один и тот же динамический ряд – уровень ВВП, который вычисляется и фиксируется ежегодно, в нашем случае исследование будет проходить на периоде с 2004-го по 2012-й гг.

Добавим к исходным данным еще один столбец, который назовем t и пометим цифрами по возрастающей порядковые номера всех зафиксированных значений ВВП за указанный период с 2004-го по 2012-й гг. – 9 лет или 9 периодов .

Эксель добавит пустое поле – разметку под будущий график, выделяем этот график и активируем появившуюся вкладку в панели меню – Конструктор , ищем кнопку Выбрать данные , в отрывшемся окне жмем кнопочку Добавить . Всплывшее окошко предложит выбрать данные для построения диаграммы. В качестве значения поля Имя ряда выбираем ячейку, которая содержит текст, наиболее полно отвечающий названию графика. В поле Значения X указываем интервал ячеек стобца t – влияющего фактора. В поле Значения Y указываем интервал ячеек столбца с известными значениями ВВП (Y) – исследуемого показателя.

Заполнив указанные поля, несколько раз нажимаем кнопку ОК и получаем готовый график динамики. Теперь выделяем правой кнопкой мыши саму линию графика и из появившегося контекстного меню выбираем пункт Добавить линию тренда

Откроется окошко для настройки параметров построения линии тренда, где среди типов моделей выбираем Линейная , ставим галочки напротив пунктов Показывать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации R2 , этого будет достаточно чтобы на графике отобразилась уже построенная линия тренда, а также математический вариант отображения модели в виде готового уравнения и показатель качества модели R 2 . Если вас интересует отображение на графике прогноза, чтобы визуально оценить отрыв исследуемого показателя укажите в поле Прогноз вперед на количество интересующих периодов.

Собственно это все, что касается этого способа, можно конечно добавить, что отображаемое уравнение линейного тренда это и есть непосредственно сама модель, которую можно использовать, в качестве формулы, чтобы получить расчетные значения по модели и соответственно точные значения прогноза (прогноз отображаемый на графике, оценить можно лишь приблизительно), что мы и сделали в приложенному к статье примере.
Построение линейного тренда с помощью формулы ЛИНЕЙН

Суть этого метода сводится к поиску коэффициентов линейного тренда с помощью функции ЛИНЕЙН , затем, подставляя эти влияющие коэффициенты в уравнение, получим прогнозную модель.
Нам потребуется выделить две рядом стоящие ячейки (на скриншоте это ячейки A38 и B38), далее в строке формул вверху (выделено красным на скриншоте выше) вызываем функцию, написав «=ЛИНЕЙН(», после чего эксель выведет подсказки того, что требуется для этой функции, а именно:
- выделяем диапазон с известными значениями описываемого показателя Y (в нашем случае ВВП, на скриншоте диапазон выделен синим) и ставим точку с запятой
- указываем диапазон влияющих факторов X (в нашем случае это показатель t, порядковый номер периодов, на скриншоте выделено зеленым) и ставим точку с запятой
- следующий по порядку требуемый параметр для функции – это определение того нужно ли рассчитывать константу, так как мы изначально рассматриваем модель с константой (коэффициент a 0 ), то ставим либо «ИСТИНА» либо «1» и точку с запятой
- далее нужно указать требуется ли расчет параметров статистики (в случае, если бы мы рассматривали этот вариант, то изначально пришлось бы выделить диапазон «под формулу» на несколько строк ниже). Указывать необходимость расчета параметров статистики, а именно стандартного значение ошибки для коэффициентов, коэффициента детерминированности, стандартной ошибки для Y, критерия Фишера, степеней свободы и пр. , есть смысл только тогда, когда вы понимаете, что они означают, в этом случае ставим либо «ИСТИНА», либо «1». В случае упрощенного моделирования, которому мы пытаемся научиться, на этом этапе прописывания формулы, ставим «ЛОЖЬ» либо «0» и добавляем после закрывающую скобочку «)»
- чтобы «оживить» формулу, то есть заставить ее работать после прописывания всех необходимых параметров, не достаточно нажать кнопку Enter, необходимо последовательно зажать три клавиши: Ctrl, Shift, Enter

Как видим на скриншоте выше, выделенные нами под формулу ячейки заполнились расчетными значениями коэффициентов регрессии для линейного тренда, в ячейке B38 находится коэффициент a 0 , а в ячейке A38 - коэффициент зависимости от параметра t (или x ), то есть a 1 . Подставляем полученные значения в уравнение линейной функции и получаем готовую модель в математическом выражении – y = 169 572,2+138 454,3*t
Чтобы получить расчетные значения Y по модели и, соответственно, чтобы получить прогноз, нужно просто подставить формулу в ячейку экселя, а вместо t указать ссылку на ячейку с требуемым номером периода (смотрите на скриншоте ячейку D25 ).
Для сравнения полученной модели с реальными данными, можно построить два графика, где в качестве Х указать порядковый номер периода, а в качестве Y в одном случае – реальный ВВП, а, в другом – расчетный (на скриншоте диаграмма справа).
Построение линейного тренда с помощью инструмента Регрессия в Пакете анализа
В статье , по сути, полностью описан этот метод, единственная же разница в том, что в наших исходных данных только один влияющий фактор Х (номер периода – t ).

Как видно на рисунке выше, диапазон данных с известными значениями ВВП выделен как входной интервал Y , а соответствующий ему диапазон с номерами периодов t – как входной интервал Х . Итоги расчетов Пакетом анализа выносятся на отдельный лист и выглядит как набор таблиц (см. рисунок ниже) на котором нас интересуют ячейки, которые были закрашены мною в желтый и зеленый цвета. По аналогии с порядком, расписанным в указанной выше статье, из полученных коэффициентов собирается модель линейного тренда y=169 572,2+138 454,3*t , на основе которой и делаются прогнозы.

Прогнозирование с помощью линейного тренда через функцию ТЕНДЕНЦИЯ
Этот метод отличается от предыдущих тем, что он пропускает необходимые ранее этапы расчета параметров модели и подстановки полученных коэффициентов вручную в качестве формулы в ячейку, чтобы получить прогноз, эта функция как раз и выдает уже готовое рассчитанное прогнозное значение на основе известных исходных данных.

В целевую ячейку (ту ячейку, где хотим видеть результат) ставим знак равно и вызываем волшебную функцию, прописав «ТЕНДЕНЦИЯ(», далее необходимо выделить , то есть , после ставим точку с запятой и выделяем диапазон с известными значениями Х, то есть с номерами периодов t , которые соответствуют столбцу с известными значениями ВВП, опять ставим точку с запятой и выделяем ячейку с номером периода, для которого мы делаем прогноз (правда, в нашем случае, номер периода можно указать не ссылкой на ячейку, а просто цифрой прямо в формуле), далее ставим еще одну точку с запятой и указываем ИСТИНА или 1 , в качестве подтверждения для расчета коэффициента a 0 , наконец, ставим закрывающую скобочку и нажимаем клавишу Enter .
Минус данного метода в том, что он не показывает ни уравнения модели, ни его коэффициентов, из-за чего нельзя сказать, что на основе такой-то модели мы получили такой-то прогноз, также как и нет какого-либо отражения параметров качества модели, того таки коэффициента детерминации, по которому можно было бы сказать имеет ли смысл брать во внимание полученный прогноз или нет.
Прогнозирование с помощью линейного тренда через функцию ПРЕДСКАЗ
Суть данной функции целиком и полностью идентична предыдущей, разница лишь в порядке прописывания исходных данных в формуле и в том, что нет настройки для наличия или отсутствия коэффициента a 0 (то есть функция подразумевает, что этот коэффициент, в любом случае, есть)

Как видно с рисунка выше, в целевую ячейку прописываем «=ПРЕДСКАЗ(» и затем указываем ячейку с номером периода , для которого необходимо просчитать значение по линейному тренду, то есть прогноз, после ставим точку с запятой, далее выделяем диапазон известных значений Y , то есть столбец с известными значениями ВВП , после ставим точку с запятой и выделяем диапазон с известными значениями Х , то есть с номерами периодов t , которые соответствуют столбцу с известными значениями ВВП и, наконец, ставим закрывающую скобочку и жмем клавишу Enter .
Полученные результаты, как и в методе выше, это лишь готовый результат расчета прогнозного значения по линейной трендовой модели, он не выдает ни погрешностей, ни самой модели в математическом выражении.
Подводя итог к статье
Можно сказать, что каждый из методов может быть наиболее приемлемым среди прочих в зависимости от текущей цели, которую мы ставим перед собой. Первые три метода пересекаются между собой как по смыслу, так и по результату, и годятся для любой более или менее серьезной работы, где необходимо описание модели и ее качества. В свою очередь, последние два метода также идентичны между собой и максимально быстро вам дадут ответ, например, на вопрос: «Какой прогноз продаж на следующий год?».



